Claude Code 실전 셋업 가이드 — 커뮤니티가 수렴한 5가지 원칙
Anthropic 해커톤 우승자, 스킬 엔지니어링 실천가, AI 연구자, 그리고 6개월간 시스템을 운영한 빌더 — 서로 다른 출발점에서 같은 결론에 도달한 Claude Code 설정 원칙 5가지.
- 배경: Claude Code를 설치하고 나면 “그래서 뭘 어떻게 설정하지?”에서 막히는 순간이 오는데, 이 설정이 생각보다 개인 취향이 아니라 구조적 결정이더라고요
- 핵심 인사이트: 서로 다른 맥락에서 Claude Code를 쓰는 사람들이 독립적으로 같은 설정 원칙에 도달했고, 그 수렴 지점이 실전 셋업의 출발선이에요
- 이런 분에게: Claude Code를 깔았는데 CLAUDE.md에 뭘 써야 할지 막막한 분, 또는 이미 쓰고 있지만 설정이 점점 복잡해져서 정리가 필요한 분
”설치는 했는데, 그래서 뭘 어떻게?”
Claude Code를 처음 설치하면 묘한 순간이 와요. 터미널에 claude를 치면 잘 뜨고, 코드도 읽고, 파일도 만들어주는데 — “이걸로 진짜 생산성을 내려면 뭘 설정해야 하지?”라는 질문에서 멈추게 되거든요.
CLAUDE.md에 뭘 써야 하는지, Skills와 Hooks는 뭐가 다른 건지, 서브에이전트는 언제 만들어야 하는지. 공식 문서를 읽어봐도 “가능하다”는 건 알겠는데 “어떤 기준으로 결정해야 하는지”는 잘 안 보여요.
저도 그랬어요. 그래서 다른 사람들은 어떻게 쓰고 있는지 살펴봤는데, 흥미로운 패턴을 발견했어요.
서로 모르는 사람들이 같은 결론에 도달한다면
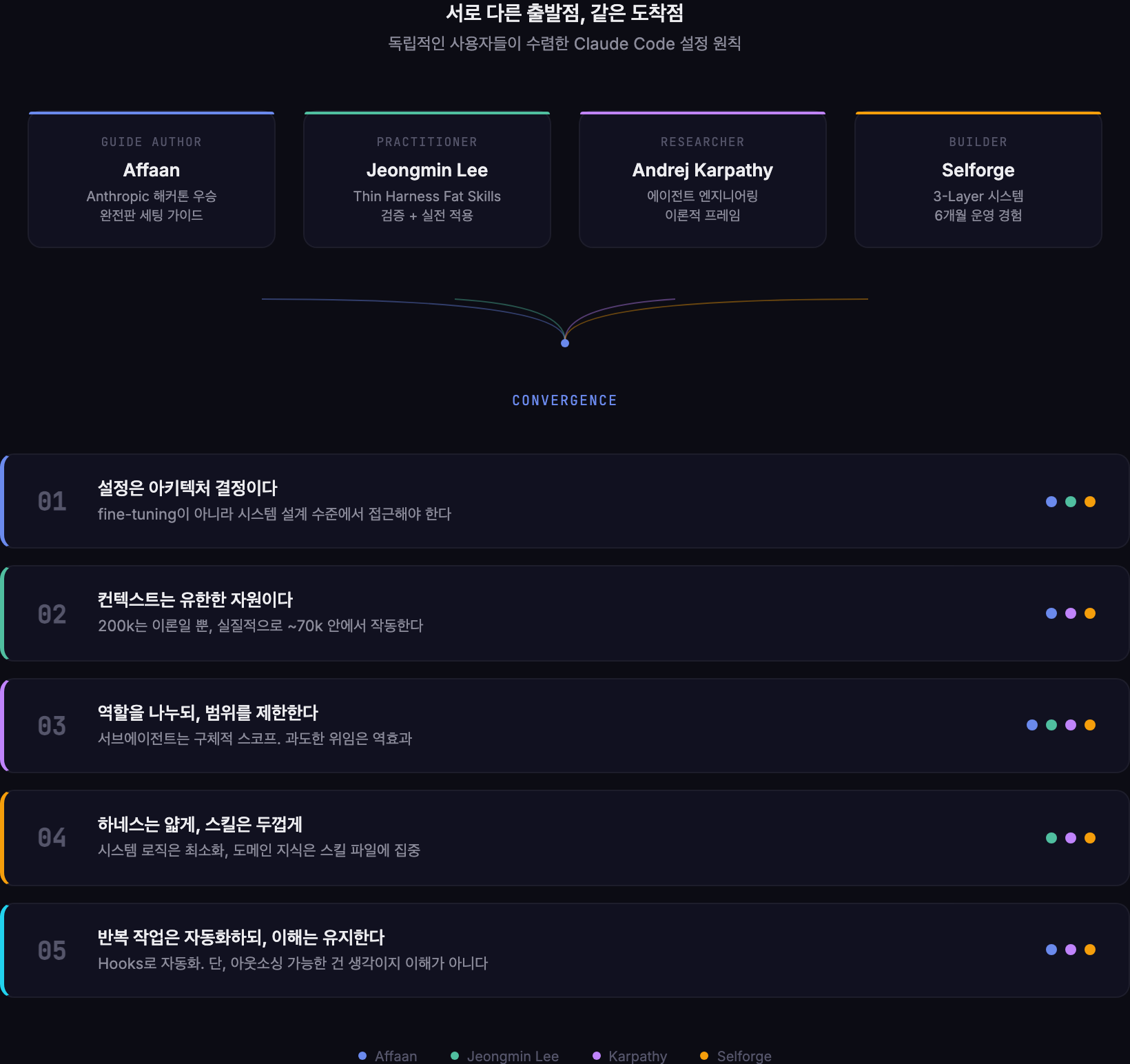
Anthropic 해커톤에서 우승한 Affaan이라는 개발자가 있어요. 이 사람이 공유한 Claude Code 완전판 세팅 가이드를 Jeongmin Lee라는 엔지니어가 직접 검증하고 소개했는데, 읽다 보니 깜짝 놀랐어요. 제가 6개월간 시행착오를 거치면서 정리한 원칙이랑 거의 같았거든요.
동시에 Andrej Karpathy가 “에이전트 엔지니어링”이라는 개념을 정리하면서 언급한 원칙들도 같은 방향을 가리키고 있었고요.
이 사람들은 서로의 작업을 참조한 게 아니에요. 각자의 맥락에서 각자의 문제를 풀다가, 독립적으로 비슷한 결론에 도달한 거예요. 한 사람의 의견이라면 “그 사람의 스타일”일 수 있지만, 여러 사람이 독립적으로 같은 곳에 도착했다면 — 거기엔 구조적인 이유가 있을 거예요.
그 수렴 지점을 5가지 원칙으로 정리해봤어요.
소스가 네 곳이에요.
- Affaan: Anthropic 해커톤 우승자. MCP 14개 운영, Skills/Hooks/Subagents 역할 분담, Rules 모듈화 등을 체계적으로 정리한 완전판 세팅 가이드를 공유했어요.
- Jeongmin Lee: Affaan의 가이드를 검증하고 실전 적용한 엔지니어. “Thin Harness, Fat Skills”라는 프레임을 소개하면서 6개의 추천 스킬을 분석했어요.
- Andrej Karpathy: “에이전트 엔지니어링”을 바이브 코딩의 상위 개념으로 정의하면서, LLM의 검증 가능성과 인간 역할의 변화를 이론적으로 정리했어요.
- Selforge: AI와 함께 사고를 확장하고 지식을 구조화하는 개인 프로젝트예요. 6개월간 에이전트 6개 + 크론 스케줄 + 채널 분리를 실전에서 다듬은 경험이에요.
이 네 소스에서 공통으로 나타나는 원칙을 추출하면 5가지로 수렴해요.
원칙 1. 설정은 아키텍처 결정이다
Claude Code 설정을 “이것저것 켜보면서 좋은 거 찾기”로 접근하면, 금방 혼란스러워져요. MCP 서버를 14개 연결하고, 스킬을 10개 만들고, 훅을 5개 걸어놓으면 — 뭐가 뭘 하는 건지 본인도 모르게 되거든요.
Affaan의 가이드에서 가장 먼저 강조하는 게 이거예요. “설정을 fine-tuning처럼 다루지 마라. 아키텍처 수준의 결정으로 다뤄라.”
fine-tuning이라고 하면 “조금씩 조정해서 최적값을 찾는” 느낌이잖아요. 근데 Claude Code 설정은 그게 아니에요. “이 프로젝트에서 AI의 역할 범위가 어디까지인가”, “어떤 작업은 자동화하고 어떤 작업은 사람이 하는가” — 이런 설계 차원의 결정이에요.
제 프로젝트(Selforge)에서도 처음에는 CLAUDE.md에 규칙을 하나씩 추가하면서 “잘 되나 보자” 식으로 접근했거든요. 그러다 규칙이 30개가 넘어가니까, 규칙끼리 충돌하기 시작했어요. 결국 전부 지우고 “이 시스템의 설계 원칙이 뭔가”부터 다시 정의해야 했어요.
Affaan의 세팅에서 핵심은 “컨텍스트 비용”이라는 관점이에요. Claude Code의 200k 컨텍스트 윈도우는 이론값이고, 실제 사용 시에는 ~70k 수준에서 작동한다는 거예요.
이 제약을 인식하면 설정 접근이 바뀌어요:
# 아키텍처 결정의 예시
## 하지 말 것 (fine-tuning 접근)
- MCP 14개 전부 활성화 → 도구 설명만으로 컨텍스트 소모
- 모든 규칙을 CLAUDE.md에 나열 → 읽기만 해도 토큰 낭비
## 할 것 (아키텍처 접근)
- MCP는 14개 설치하되 프로젝트별 5-6개만 활성화
- 미사용 MCP는 disabledMcpServers에 명시적 비활성화
- 80개 미만의 도구만 동시 실행제 프로젝트에서도 같은 일이 있었어요. CLAUDE.md가 비대해지면서 Claude가 규칙을 간헐적으로 무시하는 현상이 나타났거든요. 핵심 원칙만 CLAUDE.md에 남기고, 상세 규칙은 스킬 파일로 분리하는 구조로 바꿨어요. 이 과정은 채널 시스템으로 페르소나 분리하기에서 자세히 다뤘어요.
원칙 2. 컨텍스트는 유한한 자원이다
“200k 토큰이면 엄청 많은 거 아니야?”라고 생각하기 쉬운데, 실제로는 그렇지 않아요.
Affaan의 가이드에 따르면, 200k는 이론적 한계이고 실질적으로는 70k 정도에서 동작해요. MCP 도구 설명, CLAUDE.md 내용, 대화 기록, 파일 내용 — 이것들이 다 컨텍스트를 먹거든요. 아무 생각 없이 설정을 추가하면, 정작 중요한 작업에 쓸 컨텍스트가 부족해져요.
비유하자면, 책상 크기가 정해져 있는데 참고 자료를 너무 많이 올려놓으면 정작 작업할 공간이 없는 것과 비슷해요. 사용하지 않는 MCP를 비활성화하고, 규칙 파일을 필요한 것만 로딩하는 건 “책상 정리”에요.
Karpathy도 비슷한 맥락에서 이야기해요. LLM의 진짜 강점은 “검증 가능한 영역”에서 나오는데, 컨텍스트가 지저분하면 그 강점이 흐려진다고요.
컨텍스트 예산을 관리하는 구체적 전략이에요.
1. MCP 선택적 활성화Affaan은 14개의 MCP를 설정해뒀지만 프로젝트별로 5-6개만 활성화해요. 나머지는 settings.json의 disabledMcpServers에서 명시적으로 끄는 거예요.
{
"disabledMcpServers": ["unused-mcp-1", "unused-mcp-2"]
}이렇게 하면 도구 설명이 컨텍스트에 로딩되지 않아요. 도구가 80개를 넘어가면 Claude의 도구 선택 정확도가 떨어진다는 실험 결과도 있고요.
2. Rules 모듈화Affaan은 ~/.claude/rules/ 디렉토리에 규칙을 분리해요:
~/.claude/rules/
├── security.md
├── coding-style.md
├── testing.md
├── git-workflow.md
└── performance.md모든 규칙을 CLAUDE.md에 몰아넣는 대신, 역할별로 분리하면 필요한 규칙만 참조할 수 있어요. 저도 CLAUDE.md에는 행동 원칙과 라우팅 규칙만 남기고, 세부 동작은 .claude/skills/와 .claude/agents/로 분리했어요.
하나의 세션에서 모든 걸 하면 컨텍스트가 빠르게 소모돼요. Git Worktrees나 /fork로 대화를 분기하면 각 세션이 독립적인 컨텍스트를 갖게 돼요.
원칙 3. 역할을 나누되, 범위를 제한한다
Claude Code에서 서브에이전트를 만들 수 있다는 걸 알게 되면, “아키텍트, 코드 리뷰어, 테스터, 보안 검토자…” 역할을 잔뜩 만들고 싶어져요. 저도 그랬고요.
근데 네 소스가 모두 같은 경고를 해요 — “서브에이전트의 범위를 제한해야 한다.”
Affaan은 planner, architect, tdd-guide, security-reviewer 같은 서브에이전트를 만들되, 각각의 스코프를 엄격하게 제한해요. “모든 걸 하는 만능 에이전트”가 아니라 “한 가지를 잘하는 전문 에이전트”로요.
Karpathy의 프레임에서도 비슷한 이야기가 나와요. LLM은 “들쭉날쭉한 지능(Jagged Intelligence)“을 가지고 있어서, 검증 가능한 좁은 영역에서는 탁월하지만 넓은 판단에서는 불안정하다고요. 에이전트의 범위가 넓을수록 이 불안정한 영역에 들어갈 확률이 높아지는 거예요.
서브에이전트 스코프 제한의 실전 패턴이에요.
Affaan의 서브에이전트 구조:
.claude/agents/
├── planner.md ← 계획 수립만
├── architect.md ← 설계 결정만
├── tdd-guide.md ← 테스트 작성만
└── security-reviewer.md ← 보안 검토만각 에이전트가 “하는 것”뿐 아니라 “하지 않는 것”을 명시하는 게 핵심이에요. “이 에이전트는 코드를 직접 수정하지 않는다”, “이 에이전트는 다른 파일을 건드리지 않는다” 같은 제약이요.
제가 이걸 가장 명확하게 체감한 건 PM 역할 에이전트를 만들 때였어요. 처음에는 “PM이니까 다 할 수 있어야지”라고 넓게 정의했다가, 별도로 운영하던 사고 파트너 에이전트와 역할이 섞이는 문제가 생겼거든요. “사고/감정 관련 메시지가 오면 → 사고 파트너 쪽으로 안내”라는 경계를 명시적으로 넣고 나서야 안정됐어요. 이 과정은 채널 시스템으로 페르소나 분리하기에서 자세히 다뤘어요.
Karpathy가 말하는 “들쭉날쭉한 지능”의 실제 의미:
검증 가능한 영역 (수학, 코딩, 검색) → LLM이 탁월
검증 불가능한 영역 (미학, 판단, 취향) → LLM이 불안정
에이전트 범위가 좁을수록 → 검증 가능한 영역에 머물 확률 ↑
에이전트 범위가 넓을수록 → 불안정 영역에 진입할 확률 ↑그래서 “범위를 제한한다”는 건 단순히 정리를 위해서가 아니라, LLM의 특성에 맞는 설계 결정이에요.
원칙 4. 하네스는 얇게, 스킬은 두껍게
Jeongmin Lee가 소개한 “Thin Harness, Fat Skills”라는 개념이 있어요. 처음 들었을 때 “그게 뭔 말이지?” 싶었는데, 알고 보니 엄청 실용적인 원칙이에요.
하네스(harness)는 Claude Code의 기본 설정 — CLAUDE.md, Rules, 기본 구조 같은 거예요. 스킬(skills)은 특정 작업을 위한 전문 지식 문서고요.
“하네스는 얇게”라는 건, 기본 설정에 너무 많은 걸 넣지 말라는 거예요. “스킬은 두껍게”라는 건, 구체적인 도메인 지식과 절차는 스킬 파일에 충분히 담으라는 거예요.
왜냐하면 하네스(CLAUDE.md 등)는 매 세션마다 무조건 로딩되거든요. 여기에 내용이 많으면 컨텍스트를 상시 소모해요. 반면 스킬은 호출될 때만 로딩되니까, 두꺼워도 평소에는 비용이 없어요.
Jeongmin Lee는 “대부분 에이전트의 실제 생산성 차이는 모델이 아니라 스킬에서 갈린다”고 말하더라고요. 같은 Claude 모델을 써도, 어떤 스킬을 어떻게 구성했느냐에 따라 결과가 완전히 달라진다는 거예요.
Thin Harness, Fat Skills 패턴의 구체적 구현이에요.
Thin Harness — 매 세션마다 로딩되는 것# CLAUDE.md (얇게 유지)
## 행동 원칙 (5줄 이내)
## 채널 라우팅 (어디서 실행 중인지 확인 → 해당 스킬 로드)
## 검증 규칙 ("고쳤습니다" 선언 전 증거 필수)CLAUDE.md에는 “어떤 세션이든 반드시 지켜야 할 것”만 남겨요. 프로젝트 구조 설명, 에이전트 카탈로그 같은 건 AGENTS.md나 별도 파일로 분리하고요.
Jeongmin Lee가 추천한 6가지 스킬 패턴:
1. Anthropic 공식 스킬 ← 스킬 작성의 표준
2. Karpathy 스킬 ← 코드 품질 관리
3. Superpowers ← 브레인스토밍~코드 리뷰 전체 사이클
4. GStack ← 23개 역할별 도구 구성
5. GSD ← context rot 해결 (토큰 12K 고정)
6. Matt Pocock 스킬 ← 코딩 전 요구사항 정렬핵심은 각 스킬이 자기 완결적이라는 거예요. 스킬 파일 하나를 읽으면 그 작업에 필요한 모든 맥락이 있어야 해요. 다른 파일을 참조해야 하면 스킬의 의미가 반감돼요.
Selforge에서 이 패턴을 체감한 건 verified-fix 스킬을 만들 때였어요. 처음에는 456줄짜리 “두꺼운 버전”을 만들었는데, 기존 디버깅 스킬과 기능이 겹쳤거든요. 겹치는 부분은 기존 스킬에 위임하고, 이 스킬의 고유 가치(증거 분류, 정직한 보고)에만 집중했더니 139줄로 줄었는데 핵심 기능은 100% 유지됐어요.
두꺼운 스킬 ≠ 긴 스킬
두꺼운 스킬 = 도메인 지식이 충분한 스킬원칙 5. 반복은 자동화하되, 이해는 유지한다
Affaan의 가이드에서 Hooks를 설명하는 부분이 인상적이에요. TS 파일을 수정하면 자동으로 Prettier가 돌아가고, console.log를 남기면 경고가 뜨게 설정해놨거든요. 반복적으로 해야 하는 걸 이벤트 기반으로 자동화한 거예요.
근데 Karpathy가 여기에 중요한 단서를 달아요. “생각은 아웃소싱할 수 있지만, 이해는 아웃소싱할 수 없다.”
자동화할 수 있는 건 “이미 이해한 반복 작업”이에요. 포매팅, 린팅, 테스트 실행, 파일 정리 — 이런 건 매번 사람이 할 필요 없어요. 하지만 “왜 이 구조를 선택했는지”, “이 결정이 시스템에 어떤 영향을 미치는지”에 대한 이해까지 자동화하면 안 돼요. 그 이해가 사라지면, 자동화가 깨졌을 때 고칠 수가 없어요.
저도 크론 자동화를 많이 했는데, 어느 순간 “이 크론이 왜 이 시간에 돌아가는 거였지?”를 잊어버린 적이 있어요. 자동화가 잘 돌아갈수록 관심이 줄어들고, 관심이 줄어들면 이해가 닳더라고요. 그래서 각 크론 파일에 “왜 이 스케줄인지”를 주석으로 남기기 시작했어요.
Hooks 기반 자동화의 세 가지 레벨이에요.
Level 1: PreToolUse — 도구 실행 전 가드레일{
"hooks": {
"PreToolUse": [{
"matcher": "Write",
"command": "echo 'console.log 확인: 프로덕션 코드에 남아있지 않은지 체크'"
}]
}
}파일을 쓰기 전에 경고를 띄우거나, 특정 패턴을 차단하는 용도예요.
Level 2: PostToolUse — 도구 실행 후 정리TS 파일 수정 후 자동 Prettier, 테스트 파일 수정 후 자동 실행 같은 패턴이에요.
Level 3: Stop — 세션 종료 시 정리세션이 끝날 때 로그를 정리하거나, 상태를 기록하는 용도예요.
Karpathy의 “이해의 유지”를 구조적으로 보장하는 방법:
# 크론 파일 예시 (.claude/skills/cron/daily-check.md)
## 왜 이 스케줄인가
- 00:05에 실행: 자정 크론들이 00:00에 돌고 난 직후 점검하기 위해
- 매일 실행: CronCreate가 7일 후 만료되므로 하트비트 필요
## 무엇을 하는가
CronList를 실행하고, 등록된 작업이 6개인지 확인한다.
누락이 있으면 재등록한다.“왜”를 문서에 남기는 건 사소해 보이지만, 3개월 뒤에 이 크론이 깨졌을 때 수정할 수 있느냐 없느냐를 결정해요. 자동화의 “무엇”은 코드가 담당하지만, “왜”는 사람의 이해가 담당해야 해요. 이 부분은 항상 대화할 수 있는 환경 만들기에서 크론 하트비트 패턴을 다루면서 더 자세히 이야기했어요.
다섯 원칙을 관통하는 하나의 관점
이 다섯 가지를 관통하는 공통점이 하나 있어요. 전부 “더 많이”가 아니라 “더 정확하게”의 방향이라는 거예요.
MCP를 더 많이 연결하는 게 아니라, 필요한 것만 활성화하기. 규칙을 더 많이 쓰는 게 아니라, 핵심만 하네스에 남기기. 에이전트를 더 많이 만드는 게 아니라, 각각의 범위를 좁히기. 자동화를 더 많이 하는 게 아니라, 이해를 유지하면서 자동화하기.
Affaan의 가이드 마지막에 이런 말이 있어요. “복사가 아니라 ‘why’를 이해하고 자신의 워크플로우에 맞게 조정하세요.”
이게 가장 중요한 것 같아요. 위의 5가지 원칙도 그대로 복사하라는 게 아니에요. 자신의 프로젝트, 자신의 작업 방식에서 “왜 이 원칙이 유효한지”를 이해하고, 거기서부터 조정하는 거예요.
마무리: 설정은 한 번에 끝나지 않는다
솔직히 말하면, 이 원칙들을 “다 알고 시작한” 게 아니에요. 6개월간 시행착오를 거치면서 하나씩 체득한 거예요. CLAUDE.md가 100줄이 넘어가면서 “이러면 안 되겠다”를 깨달았고, 에이전트 5개를 한 세션에 몰아넣었다가 역할이 섞이는 걸 경험했고, 크론이 매주 깨지면서 하트비트 패턴을 만들었고요.
다른 사람들의 가이드를 읽으면서 놀란 건, 그 시행착오의 궤적이 비슷하다는 거였어요. “아, 이 사람도 여기서 막혔구나. 그리고 같은 방향으로 풀었구나.”
Claude Code 설정에 정답은 없지만, 시행착오가 수렴하는 방향은 있어요. 이 글이 그 방향을 찾는 데 도움이 됐으면 좋겠어요.
설정을 시작하셨다면 — 완벽하게 한 번에 하려고 하기보다, 하나씩 적용해보면서 자기 프로젝트에 맞는 모양을 찾아가 보세요. 그 과정 자체가 설계가 되더라고요.