익은 지식이 콘텐츠가 되기까지 — 자산화 파이프라인
지식이 쌓이는 것과 콘텐츠가 되는 것은 다른 문제예요. 매일 자정 돌아가는 크론, 숙성 시그널, 콘텐츠 파이프라인, 그리고 '자동 발행은 절대 없다'는 원칙까지 — 자산화 레이어의 전체 구조.
- 배경: 노트를 정리하고 위키까지 만들었는데, 정작 “이걸로 뭘 쓰지?”라는 질문에서 막힌 경험
- 핵심 인사이트: 지식은 일정 밀도에 도달해야 콘텐츠가 될 수 있고, 그 시점을 시스템이 알려줄 수 있다는 걸 알게 됐어요
- 이런 분에게: 메모는 많은데 콘텐츠로 연결하지 못하는 분, 또는 AI 자동 발행에 흥미는 있지만 어딘가 꺼림칙한 분
노트는 많은데 글은 안 써지는 이유
노트 앱에 메모가 수백 개 쌓여 있는데, 막상 글을 쓰려면 뭘 써야 할지 모르겠는 경험 — 다들 있잖아요.
시리즈를 처음부터 따라오셨다면, 셀포지에서 사고가 어떻게 지식으로 변하는지 흐름을 보셨을 거예요. 텔레그램으로 던진 생각이 노트로 쌓이고(시리즈 1), Graphify가 관계를 뽑아내고(시리즈 2), Wiki Agent가 위키로 정리하고(시리즈 3), Insight Agent가 내 생각과 외부 지식의 교차점을 발견하고(시리즈 4).
여기까지는 좋아요. 근데 문제가 하나 있어요. 지식이 쌓이는 것과 콘텐츠가 되는 것은 완전히 다른 문제거든요.
위키에 “에이전트 설계”라는 주제가 정리돼 있다고 해서, 그걸로 바로 글을 쓸 수 있는 건 아니에요. 자료가 너무 적을 수도 있고, 이미 다룬 주제일 수도 있고, 지금 쓰기엔 시기가 안 맞을 수도 있어요. 그래서 필요한 게 “이 주제, 지금 쓸 만해요”라고 알려주는 신호예요.
이 글에서는 그 신호가 어디서 만들어지고, 어떻게 검수되고, 최종적으로 콘텐츠가 되기까지의 전체 과정을 이야기해볼게요.
시리즈 1-4에서 다룬 데이터 흐름을 요약하면 이래요:
Raw(사람이 쓴다) → Graphify(관계 추출) → Wiki Agent(서술 위키) → Insight Agent(교차 탐색)이 파이프라인은 지식을 구조화하는 것까지만 담당해요. 자산화 레이어는 여기서 한 단계 더 나가야 해요 — “이 지식이 콘텐츠로 변환될 준비가 됐는가?”를 판단하고, 실제로 변환하는 과정이에요.
AGENTS.md의 Layer 3 정의를 보면, 자산화 레이어에는 세 개의 콘텐츠 파이프라인(웹사이트, LinkedIn, 네이버 블로그)과 PM 에이전트(셀피)가 있어요. 그리고 이 모든 파이프라인의 입구에 signals.md라는 파일이 있어요. 이게 지식 레이어와 자산화 레이어를 연결하는 다리 역할을 해요.
전체 구조는 이렇게 돼요:
[지식 레이어] [자산화 레이어]
Wiki Agent → signals.md → 셀피(검수) → 콘텐츠 파이프라인
(숙성 시그널) (5축 평가) (웹사이트/LinkedIn/네이버)“이 주제, 지금 글 쓸 만해요”
셀포지에서 이 신호를 만드는 건 signals.md라는 파일이에요.
Wiki Agent가 매일 자정에 위키를 갱신하고 나면, 부산물로 이 파일을 만들어요. “부산물”이라고 했지만 사실 꽤 중요한 역할을 해요. 이 파일에는 세 종류의 신호가 들어가거든요.
첫째, 숙성 시그널. 특정 주제에 대한 노트가 충분히 모였다는 신호예요. 예를 들어 “에이전트 설계”라는 주제에 관련 노트가 5개 이상 쌓이면, “이 주제는 글을 쓸 만큼 자료가 모였다”고 알려줘요. 과일이 익는 것과 비슷해요 — 충분히 익어야 먹을 수 있듯이, 주제도 충분히 두꺼워져야 콘텐츠가 될 수 있어요.
둘째, 허브 변화. 위키에서 가장 많이 참조되는 중심 개념(허브)의 연결이 늘어나는 걸 추적해요. 어떤 개념이 갑자기 여러 주제와 연결되기 시작하면, 그 개념을 중심으로 글을 쓸 수 있다는 뜻이에요.
셋째, 예상 못 한 연결. “에이전트 설계”와 “요리 레시피”처럼, 겉보기에 관계없어 보이는 두 주제가 실은 연결돼 있다는 발견이에요. 이런 연결은 독자에게 “어?”라는 흥미를 줄 수 있어서, 콘텐츠 소재로 좋아요.
그리고 이 시그널이 일정 기준을 넘으면, 텔레그램으로 알림이 와요. “글감이 익었어요”라는 메시지와 함께, 어떤 주제가 왜 익었는지, 그걸로 뭘 할 수 있는지까지 알려줘요.
signals.md는 Wiki Agent가 매 Ingest(위키 갱신) 후에 자동으로 재계산하는 부속 리포트예요. wiki-schema.md에 정의된 포맷은 이래요:
# 콘텐츠 신호
## God Node 변화
- [[개념]]: N edges → M edges (Δ+K)
## 숙성 시그널 (글 쓸 시점)
- [[article]] — 멤버 N개 도달, cohesion X.XX
- [[God Node]] — 엣지 N개 돌파
## Surprising Connection (confidence ≥ 0.7)
- [[A]] ↔ [[B]] — {간단 해석 제안}
## 최근 관점 진화 (Vault A 전용)
- {커뮤니티}에 {새 개념} 합류 → 반복 주제 변화 감지signals.md는 Vault A(내 사고)와 Vault B(외부 지식) 각각에 하나씩 존재해요. 역할이 달라요:
| Vault A signals.md | Vault B signals.md | |
|---|---|---|
| God Node 의미 | 반복적으로 돌아오는 내 주제 | 콘텐츠 소재 밀도 높은 개념 |
| Surprising Connection | 내 사고 속 모순이나 긴장 | 독자에게 흥미로운 연결 |
| 자산화 기여 | ”각도” 제공 | ”소재” 제공 |
숙성 시그널의 트리거 조건은 wiki-agent-b.md에 정의돼 있어요:
- 특정 커뮤니티 멤버 5개 이상 도달
- 특정 God Node 엣지 8개 이상 도달
- Surprising Connection confidence 0.8 이상 새로 등장
조건을 충족하면 텔레그램 알림이 가는데, 여기서 중요한 규칙이 하나 있어요 — 시스템 용어를 절대 쓰지 않아요. “God Node 엣지 8개 돌파”가 아니라, “흐민이 최근 포착한 글들이 하나의 주제로 모이고 있어요”라고 보내요. 알림은 기술 보고가 아니라 편집자의 제안이에요.
매일 자정, 조용히 돌아가는 것
이 신호가 만들어지려면 위키가 꾸준히 갱신돼야 해요. 셀포지에서는 매일 자정에 자동으로 이 과정이 돌아가요.
흐름은 이래요: 먼저 Graphify가 그날 새로 쌓인 노트들의 관계를 추출해요. 내 생각 창고(Vault A)와 외부 자료 창고(Vault B) 순서로요. 그다음 Wiki Agent가 변경된 부분만 위키에 반영하고, signals.md를 갱신해요.
근데 매일 돌린다고 해서 매일 위키가 바뀌는 건 아니에요. 변경이 없으면 위키 갱신을 건너뛰어요. Graphify를 돌려도 관계 데이터가 어제와 똑같으면 — 새 노트를 안 썼으니까요 — Wiki Agent를 호출할 이유가 없거든요. 괜히 같은 결과를 다시 만드는 건 자원 낭비니까요.
또 하나 재미있는 설계가 있어요. 위키 갱신에는 스위치가 있어요. .wiki_enabled라는 파일이 있어야만 위키가 갱신돼요. 이 파일을 지우면 Graphify는 돌아가되 위키 갱신은 멈춰요. 왜 이런 게 필요하냐면, 위키 구조를 크게 바꾸는 작업 중에 자동 갱신이 끼어들면 곤란하거든요. 수동으로 켜고 끌 수 있는 안전장치예요.
자정 크론(sullivan-graphify)의 전체 흐름은 이래요:
Step 0. 크론 자가 점검 (누락된 크론 재등록)
Step 1. Graphify — Vault A (Self/Raw/) 그래프 업데이트
Step 2. Graphify — Vault B (External/Raw/) 그래프 업데이트
Step 2.5. graph.json 해시 비교 (short-circuit)
Step 3. .wiki_enabled 게이트 확인
Step 4. Wiki Agent A 실행 (Vault A 변경 시)
Step 5. Wiki Agent B 실행 (Vault B 변경 시)
Step 6. git sync핵심 최적화는 Step 2.5의 해시 비교예요. 각 Vault의 graph.json SHA256 해시를 이전 실행 값과 비교해서, 변경이 없으면 Wiki Agent 호출 자체를 스킵해요:
CURRENT_HASH=$(shasum -a 256 "$GRAPH" | cut -d' ' -f1)
PREV_HASH=$(cat "$HASH_FILE" 2>/dev/null || echo "none")
echo "$CURRENT_HASH" > "$HASH_FILE"
[ "$CURRENT_HASH" = "$PREV_HASH" ] && CHANGED=false || CHANGED=true네 가지 경우의 수가 있어요:
- 둘 다 변경 없음 → Wiki Agent 전체 스킵, 로그에
NO-CHANGE기록 - Vault A만 변경 → Wiki Agent A만 실행
- Vault B만 변경 → Wiki Agent B만 실행
- 둘 다 변경 → 둘 다 실행
.wiki_enabled 게이팅은 각 Vault 독립적이에요. Vault A 위키만 끄고 Vault B 위키는 돌릴 수 있어요. 게이트에 막히면 로그에 GATED: .wiki_enabled 없음, ingest 보류를 남기고 조용히 넘어가요.
에러 대응도 계층적이에요:
- Graphify 실패 → 다음 날 자동 재시도, 별도 알림 없음
- Wiki Agent 체크리스트 실패 → 해당 article만 저장 포기, 나머지는 계속
- Wiki Agent 전체 실패 → Graphify 산출물은 유지, 위키만 다음 날 재시도
크론 자체도 자가 치유 구조예요. Step 0에서 6개 크론이 모두 등록돼 있는지 확인하고, 누락된 게 있으면 스케줄러 스킬을 읽어서 자동으로 재등록해요.
토요일 아침, 편집자의 검수
signals.md에 “이 주제가 익었다”는 신호가 쌓이면, 그 다음은 뭘까요? 바로 글을 쓸까요?
아니에요. 한 단계가 더 있어요. 셀피(PM 에이전트)가 토요일 아침마다 시그널을 검수해요.
매주 토요일 오전 9시, 셀피가 두 개의 signals.md(내 사고 + 외부 지식)를 읽고, 웹사이트 편집자 에이전트한테 “이 시그널들 중에 콘텐츠로 쓸 만한 게 있는지 봐달라”고 요청해요. 편집자는 다섯 가지 기준으로 평가해요:
- 독자 가치 — 셀포지 밖의 독자한테도 도움이 되는가?
- 소스 충분성 — 글을 쓸 만큼 자료가 쌓여 있는가?
- 기존 중복 — 이미 쓴 글과 겹치지는 않는가?
- 고유성 — 셀포지 경험에서만 나올 수 있는 이야기인가?
- 시의성 — 지금 쓰는 게 의미 있는가?
다섯 가지 중 네 개 이상 충족하면 “적합”, 두세 개면 “보류”, 하나 이하면 “부적합”이에요. 검수 결과는 텔레그램으로 오고, 제가 승인하면 그때야 글쓰기가 시작돼요.
왜 이렇게 번거롭게 할까요? 시그널이 기계적 기준(노트 5개 이상, 엣지 8개 이상)으로 생성되기 때문이에요. 숫자만으로는 “이게 정말 글이 될 수 있는가”를 판단할 수 없어요. 편집자의 눈이 필요한 거예요.
콘텐츠 시그널 검수는 selfy-콘텐츠시그널 크론으로 매주 토요일 09:00에 실행돼요. 흐름은 이래요:
1. 크론 점검 (셀피 크론 5개 확인)
2. signals.md 수집 (Vault A + Vault B)
3. site-editor evaluate 모드 호출
4. 검수 결과 텔레그램 전달
5. 흐민 응답 처리 (승인/수정/거절)site-editor의 evaluate 모드는 5축 평가를 수행해요:
| 축 | 판단 내용 |
|---|---|
| 독자 가치 | 셀포지 밖의 독자에게도 실용적 인사이트를 주는가? |
| 소스 충분성 | 해당 주제로 아티클을 쓸 만큼의 소스가 축적돼 있는가? |
| 기존 중복 | 이미 발행된 아티클/빌드 로그와 겹치는가? |
| 고유성 | 셀포지 경험에서만 나올 수 있는 이야기인가? |
| 시의성 | 지금 쓰는 것이 의미 있는가? |
판정 기준:
- 적합: 4개 이상 충족 → 콘텐츠 후보
- 보류: 2-3개 충족 → 소스 축적 후 재평가
- 부적합: 1개 이하 → 제외
검수 결과는 이런 형식으로 텔레그램에 전달돼요:
[셀피] 이번 주 콘텐츠 시그널 검수 결과
━━ 적합 (콘텐츠 후보) ━━
1. {제목안} — {추천 유형}
{왜 지금인가 한 줄}
━━ 보류 ━━
- {시그널}: {부족한 점}
━━ 편집자 코멘트 ━━
{site-editor 소견}승인이 떨어지면 site-editor의 write 모드가 호출되고, 수정 요청이 오면 피드백을 반영해서 다시 write로 넘겨요. 거절이나 무응답이면 다음 주까지 보류해요. 어떤 경우에도 사람의 판단 없이 글쓰기가 시작되지 않아요.
세 개의 출구
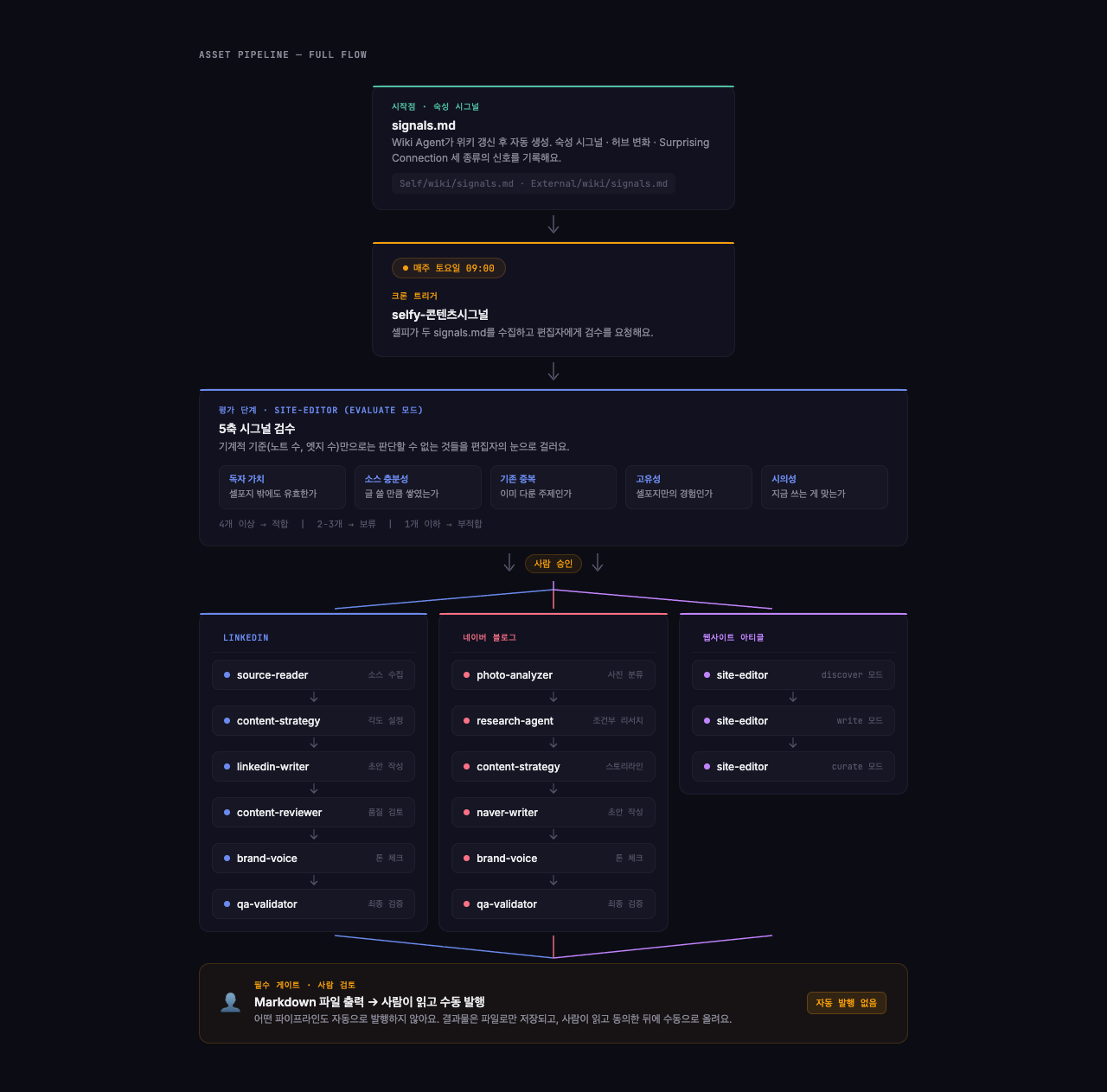
시그널이 검수를 통과하면, 실제 콘텐츠를 만드는 단계로 넘어가요. 셀포지에는 세 가지 콘텐츠 출구가 있어요.
웹사이트 아티클. 지금 읽고 계신 이 글처럼, 구현 가이드나 시행착오를 깊이 있게 풀어내는 곳이에요. 편집자 에이전트가 소스를 발굴하고, 주제를 큐레이션하고, 글을 써요.
LinkedIn 포스트. 짧고 임팩트 있는 인사이트를 전달하는 채널이에요. 여기는 다섯 단계 릴레이 구조예요 — 소스 리더가 옵시디언에서 인사이트를 수집하고, 전략가가 각도를 잡고, 작가가 글을 쓰고, 브랜드 보이스가 톤을 맞추고, 검증기가 마지막 품질 체크를 해요. 에이전트가 다섯 개나 거치는 이유는, 각 단계마다 역할이 명확히 다르기 때문이에요. 소재를 고르는 감각과 글을 쓰는 감각, 톤을 맞추는 감각은 서로 달라요.
네이버 블로그. 사진 중심의 일상 콘텐츠예요. 사진 분석기가 먼저 사진을 분류하고 스토리라인을 잡아주면, 전략가, 작가, 보이스, 검증기가 순서대로 돌아가요.
세 파이프라인의 입력과 출력은 다르지만, 공통점이 두 가지 있어요.
첫째, 모든 파이프라인에 브랜드 보이스 단계가 있어요. 어떤 채널이든 최종 아웃풋은 톤 체크를 거쳐요. “혁신적인”, “패러다임”, “게임체인저” 같은 금지어가 없는지, 가르치는 톤이 아니라 경험 공유 톤인지 확인해요.
둘째, 모든 결과물은 파일로만 저장돼요. LinkedIn API로 자동 게시하거나, 네이버에 바로 올라가거나 하는 일은 없어요. 무조건 마크다운 파일로 저장되고, 사람이 직접 읽고 확인한 뒤에 수동으로 발행해요.
세 파이프라인의 에이전트 구성을 정리하면 이래요:
웹사이트:site-editor (discover → write → curate → evaluate)site-editor는 단독 에이전트가 네 가지 모드로 동작해요. discover로 소스를 발굴하고, write로 아티클을 쓰고, curate로 기존 콘텐츠를 큐레이션하고, evaluate로 시그널을 검수해요.
LinkedIn:@source-reader → [소스 브리프 확인] → @content-strategy
→ @linkedin-writer → @content-reviewer → @brand-voice → @qa-validator소스 브리프 확인이 중요한 게이트예요. content-strategy가 실행되기 전에 오케스트레이터가 사람에게 소스 브리프를 보여주고 확인을 받아요. 핵심 소재가 뭔지, 어떤 각도로 쓸 건지를 사람이 먼저 동의해야 해요.
LinkedIn 파이프라인에는 obsidian 모드와 direct 모드가 있어요. obsidian 모드에서는 source-reader가 볼트에서 노트를 수집하고, direct 모드에서는 주제를 직접 입력해요. direct 모드에서 주제가 모호하면 content-strategy가 2-3개 방향을 제안하고, 사람이 선택한 뒤 진행해요.
네이버:@naver/photo-analyzer → @naver/research-agent(조건부)
→ @naver/content-strategy → @naver/naver-writer
→ @naver/brand-voice → @naver/qa-validator세 파이프라인의 공통 제약사항은 AGENTS.md에 명시돼 있어요:
자동 발행 절대 없음 — 결과물은 Markdown 파일로만 출력, 사람이 확인 후 수동 발행
Brand Voice 에이전트 필수 — 모든 최종 아웃풋은 Brand Voice를 통과해야 함
오케스트레이터(메인 Claude Code 세션)가 이 파이프라인을 조율해요. 서브에이전트는 다른 서브에이전트를 직접 호출할 수 없고, 오케스트레이터가 한 단계씩 넘겨줘요.
왜 자동 발행을 안 하는가
여기까지 읽으셨으면 의문이 들 수 있어요. 시그널 감지, 검수, 글쓰기까지 자동으로 돌아가는데 — 발행만 수동이라고?
맞아요. 그리고 이건 의도적인 선택이에요.
솔직히, 기술적으로 자동 발행은 어렵지 않아요. LinkedIn API를 붙이면 돼요. 네이버도 API가 있고요. 근데 안 해요.
이유는 AI slop 때문이에요.
AI가 아무리 잘 써도, 내가 읽지 않고 발행하면 그건 내 지식이 아니에요. 내 이름으로 올라가는 글인데 내가 뭘 썼는지 모른다? 그건 콘텐츠가 아니라 슬롭이에요. 양은 늘어나지만 의미는 없어요.
셀포지의 자산화 파이프라인에서 AI가 하는 일은 초안을 만드는 거예요. 소재를 모으고, 각도를 잡고, 글을 쓰고, 톤을 맞추는 것까지는 AI가 해요. 하지만 그 초안을 읽고, “이 부분은 이렇게 고치자”, “이건 내 경험과 다르다”, “이 표현이 더 맞다”고 판단하는 건 사람 몫이에요.
콘텐츠는 내가 검토하고 소화해야 진정한 의미가 있다.
이건 효율성의 문제가 아니에요. 정체성의 문제예요. 내 이름으로 나가는 글은 내가 동의하는 글이어야 해요.
사실 이 원칙은 자산화 레이어만의 이야기가 아니에요. 시리즈 전체를 관통하는 설계 원칙 중 하나가 “AI는 해석하지 않는다, 드러낸다”거든요. Wiki Agent가 “당신은 이런 사람입니다”라고 규정하지 않는 것처럼, 자산화 파이프라인도 “이 글을 발행합니다”라고 결정하지 않아요. 패턴을 드러내고, 초안을 만들고, 판단은 사람에게 남겨두는 거예요.
전체 루프
시리즈를 마무리하면서, 전체 흐름을 한번 그려볼게요.
생각이 떠오른다
↓
텔레그램으로 던진다 (포착)
↓
노트가 쌓인다 (시리즈 1)
↓
관계가 추출된다 (시리즈 2 — Graphify)
↓
위키로 정리된다 (시리즈 3 — Wiki Agent)
↓
내 생각과 외부 지식이 만난다 (시리즈 4 — Insight Agent)
↓
숙성 시그널이 생긴다 (signals.md)
↓
편집자가 검수한다 (셀피 + site-editor)
↓
콘텐츠가 만들어진다 (파이프라인)
↓
사람이 읽고 발행한다
↓
...그리고 그 과정에서 새로운 생각이 떠오른다마지막 줄이 중요해요. 이건 직선이 아니라 순환이에요.
글을 쓰면서 “아, 이 부분은 더 파봐야겠다” 하는 순간이 있어요. 검수 결과를 보면서 “이 주제는 이런 각도가 더 좋겠다” 싶을 때도 있고요. 그 생각들은 다시 텔레그램으로 가고, 노트가 되고, 위키가 되고, 또 콘텐츠가 돼요.
시리즈 1에서 “노트가 쌓이기만 한다”는 문제를 이야기했어요. 5편까지 오면서 그 노트가 어떻게 지식이 되고, 자산이 되는지를 봤어요. 근데 더 중요한 건, 이 과정이 끝나지 않는다는 거예요.
자산화가 끝이 아니에요. 자산화는 다음 사고의 시작이에요.
전체 시스템의 데이터 흐름을 정리하면 이래요:
[사고 레이어]
텔레그램 메시지 → capture-agent → Raw/ (Obsidian)
↓
[지식 레이어] ↓
sullivan-graphify 크론 (매일 00:00) ↓
├─ Graphify → graph.json ↓
├─ 해시 비교 (short-circuit) ↓
├─ Wiki Agent A → Self/wiki/ ↓
├─ Wiki Agent B → External/wiki/ ↓
└─ signals.md 갱신 ↓
↓
[자산화 레이어] ↓
selfy-콘텐츠시그널 크론 (토 09:00) ↓
├─ signals.md 수집 ↓
├─ site-editor evaluate (5축 평가) ↓
└─ 텔레그램 알림 ↓
↓ (사람 승인) ↓
콘텐츠 파이프라인 ↓
├─ 웹사이트: site-editor write ↓
├─ LinkedIn: source-reader → ... → qa-validator
└─ 네이버: photo-analyzer → ... → qa-validator
↓ ↓
Markdown 파일 출력 ↓
↓ (사람 확인 + 수동 발행) ↓
발행된 콘텐츠 ↓
↓ ↓
새로운 생각 ─────────────────────→ 처음으로이 루프에서 사람이 직접 관여하는 지점은 세 곳이에요:
- 포착: 텔레그램으로 생각을 던지는 것
- 시그널 승인: 토요일 검수 결과를 보고 진행 여부 결정
- 발행 확인: 최종 결과물을 읽고 수동 발행
나머지는 전부 자동이에요. 자정 크론이 Graphify와 Wiki를 돌리고, 토요일 크론이 시그널을 검수하고, 파이프라인이 초안을 만들어요. 하지만 사람의 판단이 빠지는 지점은 없어요.
그리고 이 루프의 마지막 화살표 — “새로운 생각 → 처음으로” — 가 이 시리즈의 핵심이에요. 자산화는 끝이 아니라 다음 사고의 입력이에요. 글을 쓰면서 생긴 새로운 질문, 검수하면서 발견한 새로운 각도, 발행 후 받은 피드백 — 이 모든 게 다시 Raw가 되고, 다시 그래프가 되고, 다시 위키가 돼요.
돌아보며
이 시리즈를 쓰면서 저도 머릿속이 정리가 됐어요.
시리즈 1에서 “노트가 쌓이기만 한다”는 불편에서 시작했어요. 2에서 관계를 뽑아냈고, 3에서 읽을 수 있는 위키로 만들었고, 4에서 내 생각과 외부 지식을 교차시켰고, 5에서 그 지식이 콘텐츠가 되는 과정을 봤어요.
돌이켜보면 이 시스템에서 가장 어려웠던 건 기술적인 부분이 아니었어요. “어디까지 자동화하고 어디서 멈출 것인가”라는 판단이 가장 어려웠어요.
전부 자동화하면 편해요. 근데 그러면 내 시스템이 아니라 AI의 시스템이 돼요. 반대로 전부 수동으로 하면 내 것이긴 한데, 지속할 수가 없어요. 그 사이의 균형 — AI가 드러내고, 사람이 판단하는 — 을 찾는 게 이 프로젝트의 본질이었어요.
혹시 비슷한 고민을 하고 계시다면, 꼭 이 구조를 따를 필요는 없어요. 중요한 건 구조가 아니라 원칙이에요. 기록의 부담을 줄이고, 연결을 자동화하되, 판단은 남겨두세요. 그러면 어떤 도구를 쓰든 비슷한 루프가 만들어질 거예요.
이 시리즈의 다른 글
- 노트가 쌓이기만 한다 — Raw의 구조와 한계
- 쌓인 노트를 지식으로 — LLM Wiki와 Graphify
- 관계를 읽을 수 있는 위키로 — Wiki Agent
- 내 생각과 외부 지식이 만나는 순간 — Insight Agent
- 익은 지식이 콘텐츠가 되기까지 — 자산화 파이프라인