노트가 쌓이기만 한다 — Raw의 구조와 한계
매일 포착한 생각과 외부 자료가 옵시디언에 쌓인다. 자동 분류되고, 출처별로 나뉘고, 깔끔하게 정리된다. 그런데 100개가 넘어가면? 쌓이는 것과 연결되는 것은 다른 문제였다.
- 배경: AI 사고 파트너와 매일 생각을 주고받다 보니, 노트가 빠르게 쌓이기 시작했어요. 정리가 문제가 아니라 “쌓인 것에서 뭘 꺼내느냐”가 문제더라고요
- 핵심 인사이트: 잘 분류된 노트도 100개가 넘으면 사람이 연결고리를 찾기 어렵다는 걸 알게 됐어요. 정리와 연결은 다른 문제였어요
- 이런 분에게: 메모 앱에 기록은 꾸준히 하는데, 쌓인 노트를 다시 펼쳐보는 일이 거의 없는 분. 또는 노트 정리 시스템을 만들어보고 싶은 분
기록은 하는데, 다시 안 보게 되더라고요
노트 앱을 쓰는 사람이라면 한 번쯤 이런 경험이 있을 거예요. 열심히 적었는데 나중에 안 본다. 검색하면 나오긴 하는데, 뭘 검색해야 할지를 모른다. 일주일 전에 적은 것도 가물가물한데, 한 달 전 메모에서 인사이트를 찾으라고요?
저도 그랬어요. 이전 시리즈에서 이야기한 것처럼, 설리반(AI 사고 파트너)한테 생각을 던지면 자동으로 분류되고 저장되는 구조를 만들었거든요. 텔레그램으로 한 줄 보내면 끝. 분류도 알아서, 저장도 알아서. 꽤 만족스러웠어요.
그런데 한 달이 지나니까 상황이 달라졌어요. 노트가 100개를 넘기기 시작했거든요. “분명 비슷한 생각을 며칠 전에도 했는데…” 하면서 파일 목록을 스크롤하고 있는 제 모습을 발견했어요. 자동 분류가 아무리 잘 돼 있어도, 노트 사이의 연결까지 알아서 해주는 건 아니더라고요.
이 글에서는 그 노트들이 어디에, 어떤 구조로 쌓이는지부터 이야기해볼게요. 구조를 먼저 이해해야 한계도 보이거든요.
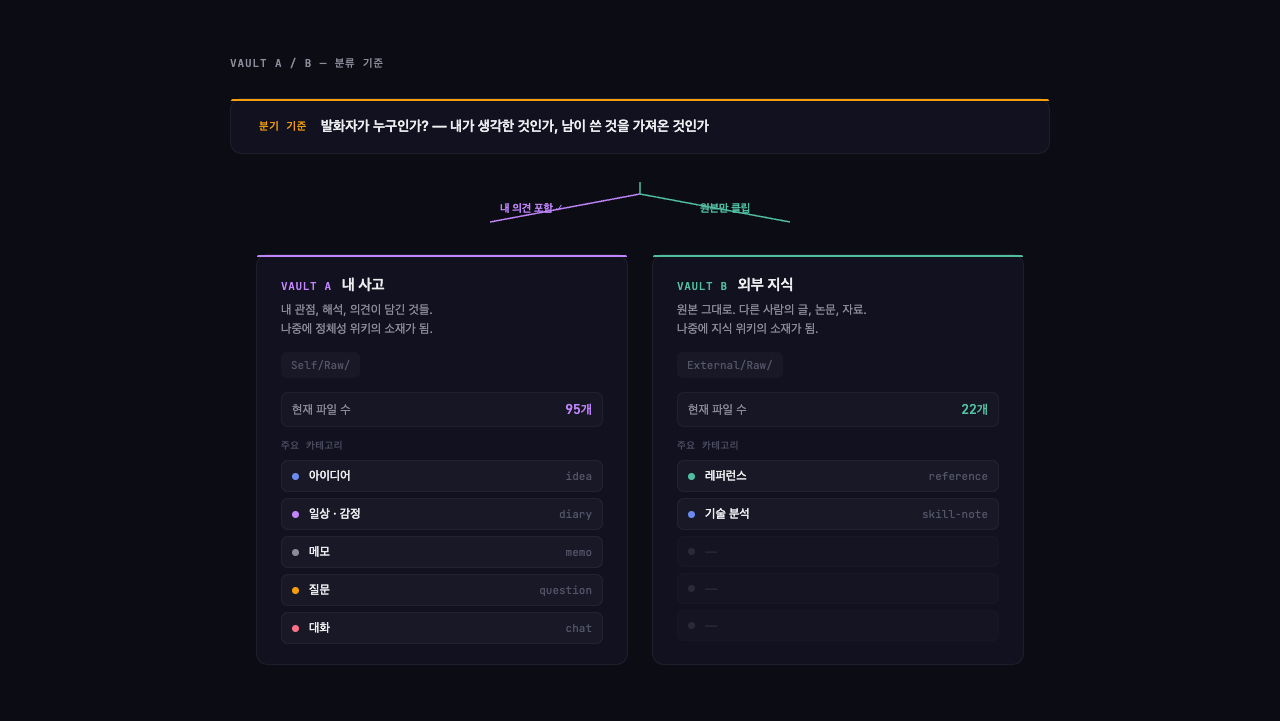
두 개의 창고: 내 생각과 외부 자료
셀포지에서 노트는 두 곳에 나뉘어 저장돼요.
- Self/Raw/ — 내 머릿속에서 나온 것. 아이디어, 감정, 질문, 일상 기록
- External/Raw/ — 바깥에서 가져온 것. 아티클 스크랩, 영상 메모, 레퍼런스 원본
구분 기준은 간단해요. 발화자가 누구인가. 내가 생각한 거면 Self, 남이 쓴 걸 가져온 거면 External.
재미있는 건 경계가 애매한 경우예요. 예를 들어 누군가의 아티클을 읽고 링크를 보내면서 “이 부분이 우리한테도 적용할 만하다”라고 한마디 붙이면, 그건 Self에 저장돼요. 내 의견이 섞인 순간 내 생각이 되니까요. 같은 링크를 코멘트 없이 URL만 보내면? External에 저장되고요.
이렇게 나누는 이유가 있어요. 나중에 돌아볼 때 “내가 한 생각”과 “외부에서 가져온 것”이 섞여 있으면 헷갈리거든요. 내 아이디어인 줄 알았는데 사실 어디서 읽은 거였다, 이런 일이 생기면 곤란하잖아요.
실제로 지금 볼트를 열어보면, Self/Raw에는 95개, External/Raw에는 22개 정도 파일이 쌓여 있어요. 내 생각이 외부 자료보다 4배 이상 많은데, 이건 매일 포착하고 회고하는 루프에서 자연스럽게 쌓인 거예요.
물리적 구조는 옵시디언 볼트 안에 두 개의 Raw 폴더로 나뉘어요.
Helen/ ← Obsidian Vault 루트
├── Self/
│ └── Raw/ ← 내 사고 (Vault A)
│ ├── 2026-03-25_capture_개발자의-전환과-현실감각.md
│ ├── 2026-03-27_capture_나를 위한 작은 일 하나.md
│ ├── 2026-04-01_briefing.md
│ ├── 2026-04-01_reflection.md
│ └── ... (95개 파일)
│
└── External/
└── Raw/ ← 외부 원본 (Vault B)
├── 2026-04-06_karpathy-llm-wiki.md
├── 2026-04-18_채용서류심사단상.md
└── ... (22개 파일)capture-agent.md에 정의된 출처 분기 로직은 이래요:
내 의견이 포함된 입력 → {VAULT}/Self/Raw/ (Vault A)
원본 소재만 있는 입력 → {VAULT}/External/Raw/ (Vault B)판단 기준은 발화자가 누구인가. 트리거가 외부 소재여도 내 의견이 붙은 순간 Vault A로 가요. 원본만 클립한 경우에만 Vault B에 저장돼요.
파일명은 [YYYY-MM-DD]_[핵심 키워드].md 패턴이고, 기존 노트를 수정하지 않아요 — vault-note-guard.sh 훅이 덮어쓰기를 차단해요. 노트는 한 번 쓰면 그대로 남는 append-only 구조예요.
자동으로 붙는 분류표
노트를 저장할 때 AI가 자동으로 카테고리를 붙여줘요. 직접 지정할 수도 있고, 안 하면 내용을 보고 알아서 판단해요.
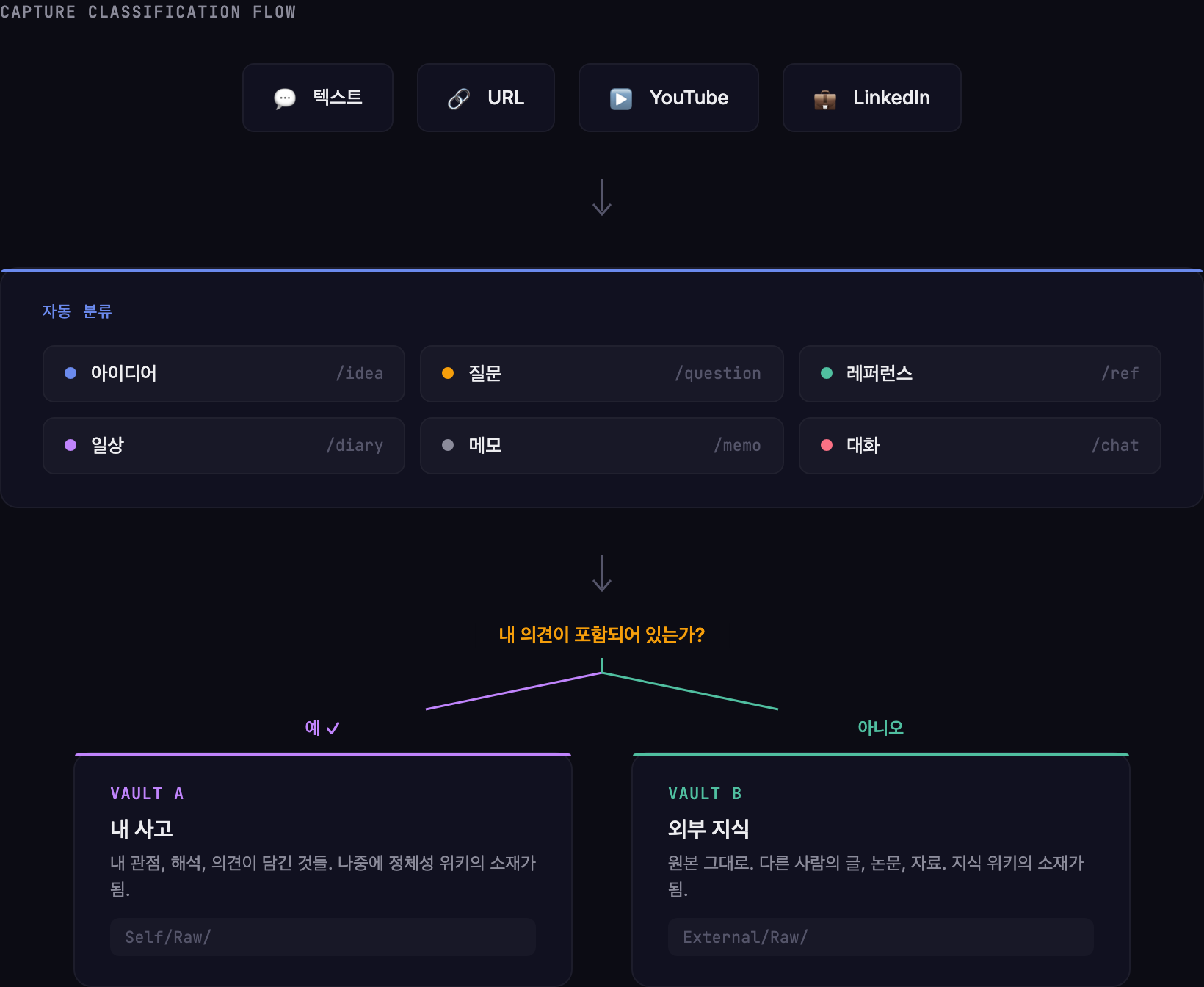
카테고리는 이런 것들이에요:
- 아이디어 — 아직 검증 안 된 새로운 생각. “이런 건 어떨까?”
- 질문 — 답을 모르거나 탐색하고 싶은 것. “왜 이럴까?”
- 레퍼런스 — 외부 자료, 링크, 인용
- 일상 — 기분, 상태, 에너지 기록
- 메모 — 단순 기록. 장 볼 리스트, 약속 시간 같은 것
- 대화 — 자유 대화 후 자동 저장되는 요약
실제로 한 달치 노트를 열어보면, 아이디어가 10개로 가장 많고, 레퍼런스 5개, 메모 6개, 감정 1개 이런 분포예요. 따로 신경 쓰지 않아도 “요즘 내가 뭘 많이 생각하는지”가 숫자로 드러나더라고요.
카테고리를 직접 지정하고 싶으면 메시지 맨 앞에 /idea, /ref, /memo 같은 커맨드를 붙이면 돼요. 근데 솔직히 대부분은 안 붙여요. 그냥 보내면 AI가 내용을 보고 판단하거든요.
메모(/memo)는 좀 특별한데, 회고에서 빠져요. “오후 3시 미팅” 같은 단순 기록이 밤 회고에 등장하면 맥락이 흐려지니까요. 대신 “리마인드 해줄까?”라고 물어봐서, “내일 아침”이라고 답하면 그때 다시 알려줘요.
capture-agent.md의 분류 시스템은 두 가지 경로로 동작해요.
커맨드 분류
메시지 첫 토큰이 /xxx 형태면 카테고리 커맨드로 인식해요:
/idea → 아이디어
/question → 질문
/ref → 레퍼런스
/diary → 일상
/memo → 메모 (회고 제외 + 리마인드 제안)
/chat → 대화 모드 진입 후 종료 시 자동 저장본문 중간의 /xxx는 커맨드가 아니에요. 첫 토큰만 확인해요. 미정의 커맨드(/xxx)는 커스텀 카테고리가 돼요 — 새 분류를 바로 만들 수 있는 거예요.
자동 분류
커맨드가 없으면 AI가 내용을 보고 판단해요. 판단 기준:
- 새로운 관점이나 가능성 → 아이디어
- 답을 모르거나 탐색 대상 → 질문
- 외부 자료, 링크, 인용 → 레퍼런스
- 기분, 상태, 에너지 → 일상
- 단순 기록, 리마인드 대상 → 메모
노트 frontmatter
모든 노트에 이런 메타데이터가 붙어요:
---
type: capture
category: 아이디어
date: 2026-03-25 18:41
source: text
tags: [키워드1, 키워드2, 키워드3]
---type은 노트의 종류(capture, briefing, reflection, work-note 등), category는 분류, source는 입력 형태(text, url, youtube)예요. 이 구분이 나중에 회고나 브리핑에서 노트를 선별하는 기준이 돼요.
메모 리마인드
/memo 저장 후 → “리마인드 해줄까?” → 자연어 시간 응답(“내일 아침”, “3시간 후”) → CronCreate(recurring=false)로 일회성 크론 등록. 해당 시각에 텔레그램으로 원본 내용을 다시 보내줘요. 2분 무응답이면 자동 종료.
소스별로 다르게 처리돼요
텔레그램으로 보내는 것이 텍스트만은 아니에요. URL을 보내기도 하고, 유튜브 링크를 보내기도 하고, 링크드인 게시물을 공유하기도 해요. 각각 처리 방식이 달라요.
- 텍스트: 그대로 분류하고 저장해요. 가장 단순해요.
- URL (아티클이나 문서): 링크를 열어서 본문을 가져오고, 제목과 요약을 만들어서 저장해요.
- 유튜브 링크: 영상 제목을 추출해서 URL과 함께 저장해요. 같이 적은 메모가 있으면 함께 넣고요.
- 링크드인 게시물: 이건 좀 까다로워요. 일반적인 방법으로는 접근이 안 돼서, 로그인된 브라우저로 직접 열어서 본문을 가져와요.
예를 들어 채용 관련 링크드인 게시물을 보내면, AI가 브라우저를 열어서 본문을 읽고, 요약해서 노트로 만들어요. 실제로 이런 노트가 만들어져요:
채용 서류심사를 하며 느낀 몇 가지 단상 신입사원 서류심사에서 발견한 6가지 문제: 문장 구조 붕괴, AI 사용 흔적 미가공, 차별화 감소… 핵심 결론: “좋은 자기소개서는 자신의 실제 생각과 리얼한 경험을 보여주는 글.”
코멘트 없이 링크만 보냈으니, 이 노트는 External/Raw에 저장됐어요.
capture-agent.md는 입력 유형에 따라 다른 처리 파이프라인을 적용해요:
| 소스 | 처리 방식 | 비고 |
|---|---|---|
| 텍스트 | 요약 + 분류 | 가장 단순 |
| URL | WebFetch → 본문 추출(최대 3000자) → title + summary | 접근 실패 시 텍스트 fallback |
| YouTube | WebFetch → 페이지에서 제목 추출 → 제목 + URL 저장 | 함께 적은 메모 포함 |
Playwright + storage-state.json → 본문 추출 | WebFetch 접근 불가 |
LinkedIn 처리가 특이한데, 일반 웹 스크래핑으로는 로그인 벽에 막혀요. 그래서 Playwright로 headless 브라우저를 띄우고, 저장해둔 로그인 상태(storage-state.json)를 로드해서 접근해요.
1. chromium.launch({ headless: true, channel: 'chrome' })
2. browser.newContext({ storageState: storage-state.json })
3. page.goto(URL, { waitUntil: 'domcontentloaded' })
4. 본문 추출 → 요약 → 노트 생성쿠키가 만료되면(회원가입 페이지로 리다이렉트) persistent context로 재로그인 후 storageState를 다시 내보내는 자가 복구 로직도 있어요.
실제로 어떤 노트들이 쌓이나
구조를 설명하는 것보다 실제 예시를 보는 게 감이 올 거예요. 한 달 동안 실제로 쌓인 노트 몇 개를 보여드릴게요.
아이디어 — 비행기에서 떠오른 생각
개발자의 전환과 현실 감각 비행기에서 클로드코드를 쓰다가 떠오른 두 갈래의 생각. 하나는 직업적 전환에 대한 것 — “개발자의 역할이 코드를 짜는 사람에서 AI가 잘 일할 수 있는 시스템을 설계하는 사람으로 이동하고 있다.” 하나는 삶의 밀도에 대한 것 — “키보드 밖 현실 시간을 의도적으로 늘려야 한다.”
텔레그램에 두 문단 정도 썼을 뿐인데, AI가 요약하고 핵심 포인트를 뽑아서 노트로 만들었어요. 카테고리는 자동으로 “아이디어”가 붙었고, Self/Raw에 저장됐어요.
감정 — 자기 돌봄의 조용한 다짐
나를 위한 작은 일 하나 “내일은 그냥 뭐라도, 내가 나를 위해 하고 싶은 작은 일이라도 해보려고.” 결과나 성과보다 ‘나를 위한다’는 감각 자체가 목적.
딱 한 줄 보낸 거예요. 그런데 AI가 이 한 줄에서 감정을 읽고 “일상”이 아닌 “감정”으로 분류했어요. 거창한 계획이 아니라 조용한 다짐이라는 맥락을 파악한 거죠.
레퍼런스 — 외부에서 가져온 자료
Karpathy LLM Wiki LLM이 점진적으로 구축하는 마크다운 기반 개인 지식 베이스. RAG의 대안. 핵심 전제: “컴파일된 지식이 실시간 검색보다 낫다.”
이건 External/Raw에 저장된 노트예요. Karpathy의 LLM Wiki 아이디어를 정리한 건데, 내 의견 없이 원본 내용만 요약한 거라 외부 창고에 들어갔어요.
메모 — 단순 기록
쪼매매운냉면집 손만두 후기 냉면 맛집 기록. 회고 컨텍스트에서 제외.
이런 것도 섞여 있어요. 맛집 기록이 밤 회고에 나오면 좀 이상하잖아요. 그래서 /memo로 저장하면 회고에서 자동으로 빠져요.
work-note — 작업 과정의 기록
사실 캡처만 쌓이는 건 아니에요. 작업 중에 생기는 시행착오와 해결 과정도 work-note로 기록돼요. Self/Raw에 22개 정도 있는데, 이런 것들이에요:
photo-hallucination-prevention — 사진 분석 시 AI 할루시네이션 방지 로직 channel-relay-asymmetry — 채널 간 메시지 전달의 비대칭 문제
이런 노트들은 나중에 아티클이나 가이드의 소재가 되기도 해요.
한눈에 보는 구조
지금까지 이야기한 구조를 정리하면 이래요:
텔레그램 메시지
↓
capture-agent (자동 분류 + 출처 분기)
↓
┌─────────────────────────────────────────┐
│ Self/Raw/ (내 사고) 95개 파일 │
│ ├── capture (25개) 아이디어, 질문, │
│ │ 감정, 일상, 메모 │
│ ├── work-note (22개) 작업 시행착오 │
│ ├── briefing (13개) 아침 브리핑 │
│ ├── reflection (7개) 밤 회고 │
│ └── weekly (2개) 주간 회고 │
│ │
│ External/Raw/ (외부 원본) 22개 파일 │
│ ├── capture (13개) 레퍼런스 원본 │
│ └── skill-note (6개) 기술 분석 │
└─────────────────────────────────────────┘깔끔하죠? 분류도 잘 돼 있고, 내 생각과 외부 자료가 물리적으로 분리돼 있고, 각 노트에는 메타데이터가 붙어 있어요. 시스템으로서는 꽤 잘 돌아가고 있어요.
근데요.
100개가 넘으면 생기는 문제
노트가 30개쯤일 때는 괜찮았어요. 파일 목록을 훑으면 대충 뭐가 있는지 감이 오니까요. 50개쯤 되니까 좀 버거워졌어요. 100개가 넘어가니까 사실상 불가능해졌어요.
문제 1: 비슷한 생각을 했다는 건 아는데, 어디 있는지 모른다
“분명 며칠 전에 비슷한 아이디어를 적었는데…” 하면서 파일을 하나씩 열어봐요. 제목만으로는 내용을 다 알 수 없으니까요. “개발자의 전환과 현실 감각”이라는 제목에 AI 시스템 설계 이야기가 들어 있다는 걸, 열어보기 전에는 몰라요.
문제 2: 서로 다른 노트 사이의 연결이 안 보인다
비행기에서 적은 “AI가 잘 일할 수 있는 시스템을 설계하는 사람으로 이동하고 있다”는 아이디어와, External/Raw에 있는 Karpathy의 LLM Wiki 아이디어가 사실은 깊이 연결돼 있거든요. 둘 다 “AI와 사람의 역할 분리”라는 같은 줄기인데, 한 달 사이에 다른 맥락에서 적었으니 연결이 안 보여요.
문제 3: 패턴이 있는데 드러나지 않는다
한 달치 노트를 분석해보면, 아이디어 10개 중 7개가 “시스템 설계” 관련이에요. 이건 주간 회고에서 잠깐 포착되긴 하지만, 한 달, 두 달, 석 달에 걸친 큰 흐름은 사람이 직접 읽어서는 찾기 어려워요.
정리를 잘 해두면 찾기 쉬울 거라고 생각했어요. 카테고리도 있고, 날짜도 있고, 태그도 있으니까요. 근데 실제로 노트가 쌓이면 정리의 문제가 아니라 연결의 문제라는 걸 알게 됐어요.
폴더 구조가 아무리 깔끔해도, 두 노트 사이에 “이 생각과 저 생각이 같은 줄기다”라는 연결은 폴더에 담기지 않거든요. 태그로 해결할 수 있을까 싶지만, 태그는 미리 정해둔 분류일 뿐이에요. “이 두 노트가 왜 연결되는지”를 설명해주지는 않아요.
결국 노트가 많아질수록, 사람이 직접 모든 노트를 읽고 연결고리를 찾는 건 현실적이지 않더라고요. 자동으로 해줄 누군가가 필요해요.
구조적으로 보면, 현재 Raw 볼트의 한계는 명확해요:
-
Flat 저장: Self/Raw 아래 95개 파일이 하위 폴더 없이 나란히 있어요.
typefrontmatter로 구분하지만, 물리적으로는 같은 레벨에 쌓이는 구조예요. -
연결 부재: 노트 간 링크나 관계 정보가 없어요. 옵시디언의
[[위키링크]]를 쓰면 수동으로 연결할 수 있지만, 캡처 에이전트는 의도적으로 이걸 하지 않아요.capture-agent.md에 명시돼 있어요 — “노트 간 연결은 지식 레이어(Graphify + Wiki Agent)가 담당하므로 여기서는 하지 않는다.” -
검색의 한계: 키워드 검색은 가능하지만, 의미적 유사성(semantic similarity)은 잡을 수 없어요. “AI 시스템 설계”와 “LLM Wiki”가 같은 맥락이라는 건 내용을 읽어야 알 수 있는 거예요.
-
시간 스케일의 한계: 주간 회고가 7일치 패턴을 찾아주긴 하지만, 한 달 이상의 장기 패턴은 현재 구조로는 포착이 어려워요.
이건 설계상 의도된 분리예요. AGENTS.md의 아키텍처를 보면:
Raw/ (사람이 쓴다)
↓
Graphify → graphify-out/graph.json (관계 추출만)
↓
Wiki Agent → wiki/ (Wikipedia 스타일 서술)Raw는 원재료 저장소이고, 연결과 패턴 추출은 다음 레이어의 일이에요. 이 분리가 있어야 원본이 오염되지 않아요.
Raw는 원재료일 뿐이에요
돌이켜보면, Raw 폴더를 “완성된 지식 창고”로 기대한 게 잘못이었어요. Raw는 이름 그대로 **원재료(raw material)**예요. 잘 분류되고, 깔끔하게 저장되고, 메타데이터가 붙어 있지만 — 그래도 원재료는 원재료예요.
밀가루, 설탕, 달걀이 아무리 깔끔하게 정리돼 있어도 케이크가 되려면 누군가 섞고 구워야 하잖아요. 노트도 마찬가지예요. 잘 쌓여 있는 것과 지식이 되는 것은 다른 문제더라고요.
그래서 셀포지에서는 이 원재료를 가지고 자동으로 연결을 찾고, 관계를 정리하고, 위키처럼 편집해주는 구조를 따로 만들었어요. Raw 위에 올라가는 다음 레이어가 있는 거예요.
다음 편에서는 이 쌓인 노트들에서 자동으로 관계를 추출하고 연결해주는 구조를 다뤄볼게요. 100개 넘는 노트를 사람 대신 읽고, “이 생각과 저 생각이 같은 줄기예요”라고 알려주는 존재 — Graphify와 LLM Wiki 이야기예요.