영속성 체인으로 세션 안정성 확보 — AI가 꺼지지 않게 만드는 4레이어
'크론이 만료되면 크론을 재등록할 주체가 없다' — 이 순환 의존을 끊는 4레이어 인프라와 3중 하트비트 설계. 재부팅해도 살아남는 AI 시스템.
- 배경: AI 사고 파트너를 24시간 운영하려 했는데, 컴퓨터를 재부팅하면 죽고, 스케줄이 7일 후 만료되면 재등록할 주체가 없는 순환 의존 문제에 부딪혔어요
- 핵심 인사이트: “언제든 깨질 수 있다”고 가정하고, 각기 다른 레이어에서 서로를 살리는 구조를 만들면 시스템 영속성을 확보할 수 있었어요
- 이런 분에게: AI 에이전트를 자동 스케줄로 운영하고 있는데, 세션이 죽거나 크론이 만료될 때마다 수동으로 재시작하고 있는 분
크론이 만료되면, 누가 크론을 살리나요
AI 사고 파트너 설리반(Sullivan)을 텔레그램으로 24시간 운영하기 시작했을 때, 처음에는 잘 됐어요. 매일 아침 브리핑이 오고, 점심에 체크인이 오고, 자정에는 하루 동안 쌓인 생각들을 정리해줬죠.
근데 일주일쯤 지나니까, 아침 브리핑이 안 오는 거예요.
확인해보니 스케줄이 만료돼 있었어요. Claude Code의 CronCreate는 7일 후에 자동으로 만료되거든요. “아, 그러면 스케줄이 만료되기 전에 재등록하면 되겠다” — 여기까지는 쉽게 생각했어요. 아침 브리핑 크론에 “스케줄 만료되면 재등록해”라는 지시를 넣어두면 되니까요.
그런데 한 발짝 더 생각하니까 문제가 보이더라고요. 아침 브리핑 크론 자체가 만료되면, 재등록 명령을 실행할 주체가 없는 거예요. 달걀이 닭을 낳고, 닭이 달걀을 낳는데, 둘 다 죽으면? 아무것도 태어나지 않아요.
이건 단순히 “크론을 다시 등록하면 되지”로 풀리는 문제가 아니었어요.
셀포지의 AI 사고 파트너 설리반은 Claude Code의 채널 모드로 텔레그램에 연결돼 있어요. CronCreate로 반복 스케줄을 등록해서 아침 브리핑, 점심 체크인, 자정 그래프 빌드 등을 자동 실행하는 구조예요.
문제는 CronCreate의 recurring=true 작업이 7일 후 자동 만료된다는 거예요. 아침 브리핑 크론 프롬프트에 “CronList를 확인하고 누락된 스케줄을 재등록하라”는 지시를 넣어뒀는데, 이 아침 브리핑 크론 자체가 만료되면 재등록 명령을 실행할 주체가 사라져요.
CronCreate(recurring=true) → 7일 후 만료
→ 크론 프롬프트에 "만료 시 재등록" 지시
→ 그 크론 자체가 만료되면?
→ 재등록 명령을 실행할 수 없음
→ 순환 의존 (deadlock)이 순환 의존을 끊고, 재부팅과 장애까지 견디는 인프라를 만든 과정이에요.
세 가지 다른 종류의 “죽음”
문제를 정리해보니, “AI가 죽는” 상황이 하나가 아니라 세 가지였어요.
첫째, 세션이 꺼지는 것. 컴퓨터를 재부팅하거나 터미널을 닫으면, 설리반이 돌아가던 프로세스 자체가 사라져요. 이건 마치 사무실을 닫으면 직원도 퇴근하는 것과 비슷한데 — 문제는 이 직원이 24시간 근무해야 한다는 거예요.
둘째, 세션이 멈추는 것. 프로세스는 살아있는데 텔레그램 메시지를 처리하지 못하는 상태. 겉으로는 멀쩡한데 실제로는 일을 안 하고 있어요. 밀린 메시지가 쌓이기 시작하면, 저는 그걸 모르고 계속 메시지를 보내고 있는 거죠.
셋째, 스케줄이 만료되는 것. 위에서 말한 7일 만료 문제예요. 세션은 살아있고 메시지도 처리하는데, 자동으로 브리핑을 보내거나 그래프를 빌드하는 기능이 조용히 사라져요.
이 세 가지를 각각 다른 레이어에서 해결해야 했어요. 하나의 해결책으로 세 문제를 동시에 풀 수는 없었거든요.
영속성 문제를 3개 레이어로 분해했어요:
| 문제 | 증상 | 원인 |
|---|---|---|
| 세션 영속성 | 재부팅 후 설리반 미응답 | claude 프로세스가 터미널 종료와 함께 사망 |
| 장애 복구 | 프로세스는 있지만 메시지 처리 안 됨 | 텔레그램 API 응답 지연, 내부 상태 이상 |
| 스케줄 영속성 | 7일 후 자동 브리핑 중단 | CronCreate 7일 만료 + 순환 의존 |
특히 세 번째 문제가 흥미로웠어요. 아침 브리핑 프롬프트에 “스케줄 만료되면 재등록해”를 넣어뒀지만, 그 아침 브리핑 cron 자체가 만료되면 재등록을 트리거할 주체가 없어요. 스스로를 살리는 구조는 자기 자신이 죽으면 작동하지 않아요.
4레이어 인프라 설계
해결 방법은 간단한 원리에서 출발했어요. “자기 자신을 살릴 수 없으면, 남이 살려줘야 한다.”
집에서 나갈 때 문이 잠겼는지 확인하는 것처럼 — 한 번만 확인하면 불안하고, 두세 번 확인하면 마음이 놓이잖아요. 시스템도 마찬가지였어요. 한 겹만으로는 불안하니까, 겹겹이 쌓았어요.
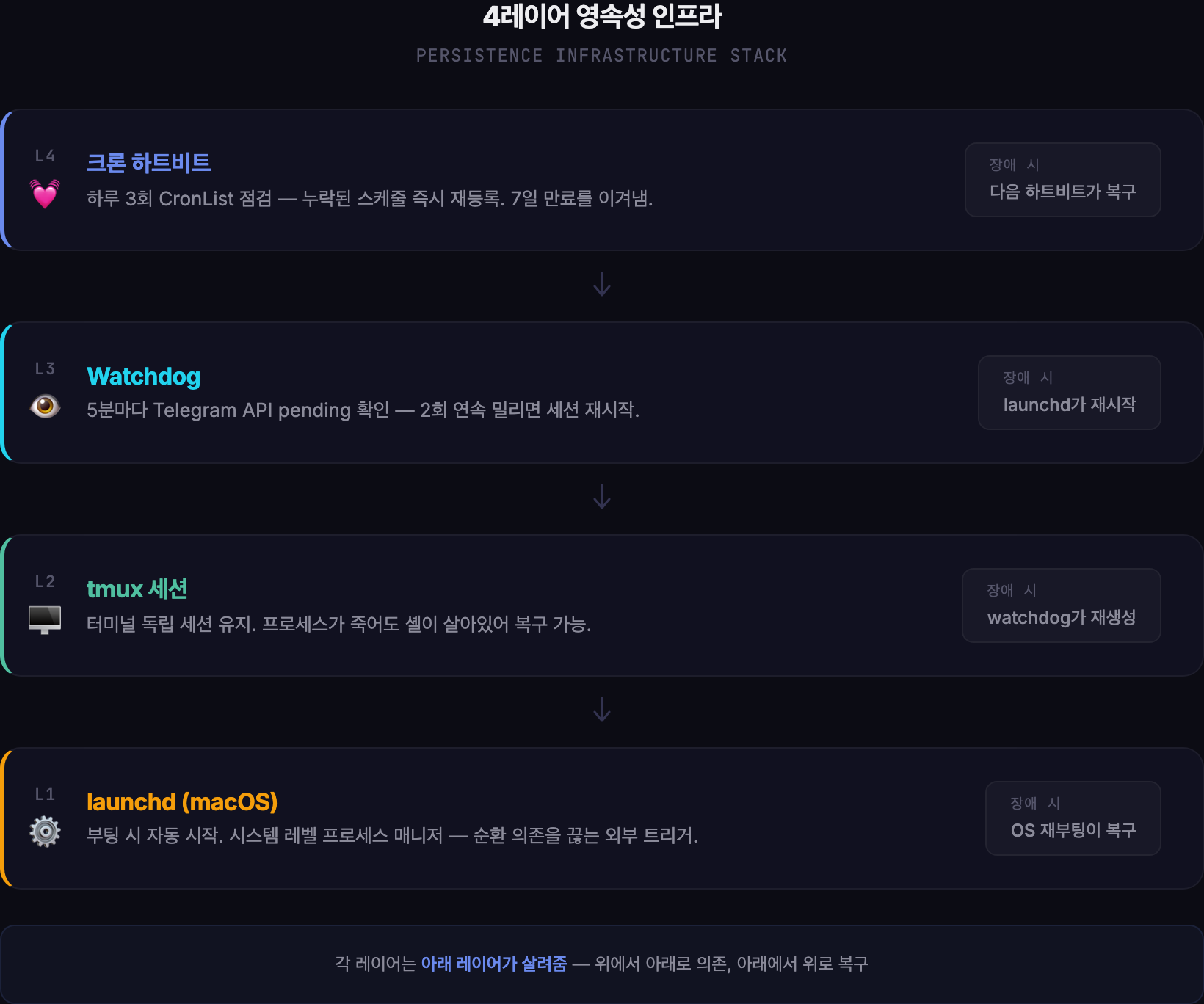
맨 아래: 부팅 시 자동 시작 (launchd). 컴퓨터가 켜지면 macOS가 알아서 설리반을 깨워요. 사람이 뭘 하지 않아도요. 이게 가장 바닥에 있는 안전망이에요.
그 위: 세션 유지 (tmux). 터미널을 닫아도 프로세스가 죽지 않게 해주는 장치예요. 설리반이 돌아가는 “방”을 만들어두고, 제가 방에서 나가도 방은 계속 유지되는 거죠.
그 위: 감시자 (watchdog). 5분마다 “설리반 괜찮아?” 하고 확인해요. 텔레그램 API에 밀린 메시지가 있는지 보고, 2번 연속 밀려있으면 세션을 재시작해요.
맨 위: 하트비트 (크론 점검). 하루에 세 번, “스케줄 다 살아있지?” 하고 확인해요. 만료된 게 있으면 즉시 재등록해요.
핵심은 이거예요 — 각 층이 아래층을 의지해요. 하트비트가 죽으면 watchdog가 살리고, watchdog가 죽으면 launchd가 살리고, launchd가 죽으면… 그건 OS가 죽은 거니까 재부팅하면 돼요.
4개 레이어를 각각 독립된 관심사로 분리했어요:
[launchd: com.hminn.sullivan-channel]
→ start.sh
→ tmux new-session -d -s sullivan-channel
→ tmux send-keys "claude --channels ..." Enter
[launchd: com.sullivan-channel.watchdog] (5분 간격)
→ watchdog.sh
→ Telegram API pending_update_count 확인
→ 2회 연속 밀림 → 세션 재시작
[launchd: com.sullivan-channel.renew-schedule] (5일 간격)
→ renew-schedule.sh
→ tmux send-keys로 재등록 명령 전송launchd는 macOS의 시스템 프로세스 매니저예요. RunAtLoad: true로 부팅 시 자동 실행되고, KeepAlive 정책으로 프로세스 사망 시 재시작해요. 이 레이어가 순환 의존을 끊는 외부 트리거 역할을 해요 — CronCreate와 무관하게 OS 레벨에서 동작하니까요.
tmux는 터미널 멀티플렉서. tmux new-session -d + tmux send-keys 조합으로 백그라운드 세션을 생성하고 claude를 실행해요. 프로세스가 죽어도 tmux 세션(셸)은 유지돼서, watchdog가 같은 세션에 새 프로세스를 띄울 수 있어요.
watchdog는 5분마다 텔레그램 Bot API의 getUpdates로 pending_update_count를 확인해요. 2회 연속 밀려있으면 세션이 멈춘 것으로 판단하고, tmux 세션을 kill 후 재생성해요.
스케줄 갱신은 5일마다 launchd가 tmux에 send-keys로 재등록 프롬프트를 전송해요. CronCreate의 7일 만료 전에 갱신하는 구조. 세션은 끊기지 않고 Claude가 프롬프트를 받아 CronCreate를 다시 실행해요.
3중 하트비트 — 하루에 세 번 확인하기
4레이어 인프라로 세션이 죽는 문제는 해결했어요. 그런데 스케줄 만료 문제는 좀 더 세밀한 접근이 필요했어요.
5일마다 launchd가 재등록 명령을 보내니까 이론적으로는 괜찮은데 — “이론적으로 괜찮다”를 믿으면 안 되더라고요. 실제로 뭔가 잘못되는 건 항상 이론의 틈새에서 일어나거든요.
그래서 보험을 추가했어요. 설리반의 일상 크론들 — 자정 그래프 빌드, 아침 브리핑, 점심 체크인 — 에 각각 “스케줄 점검” 단계를 넣었어요.
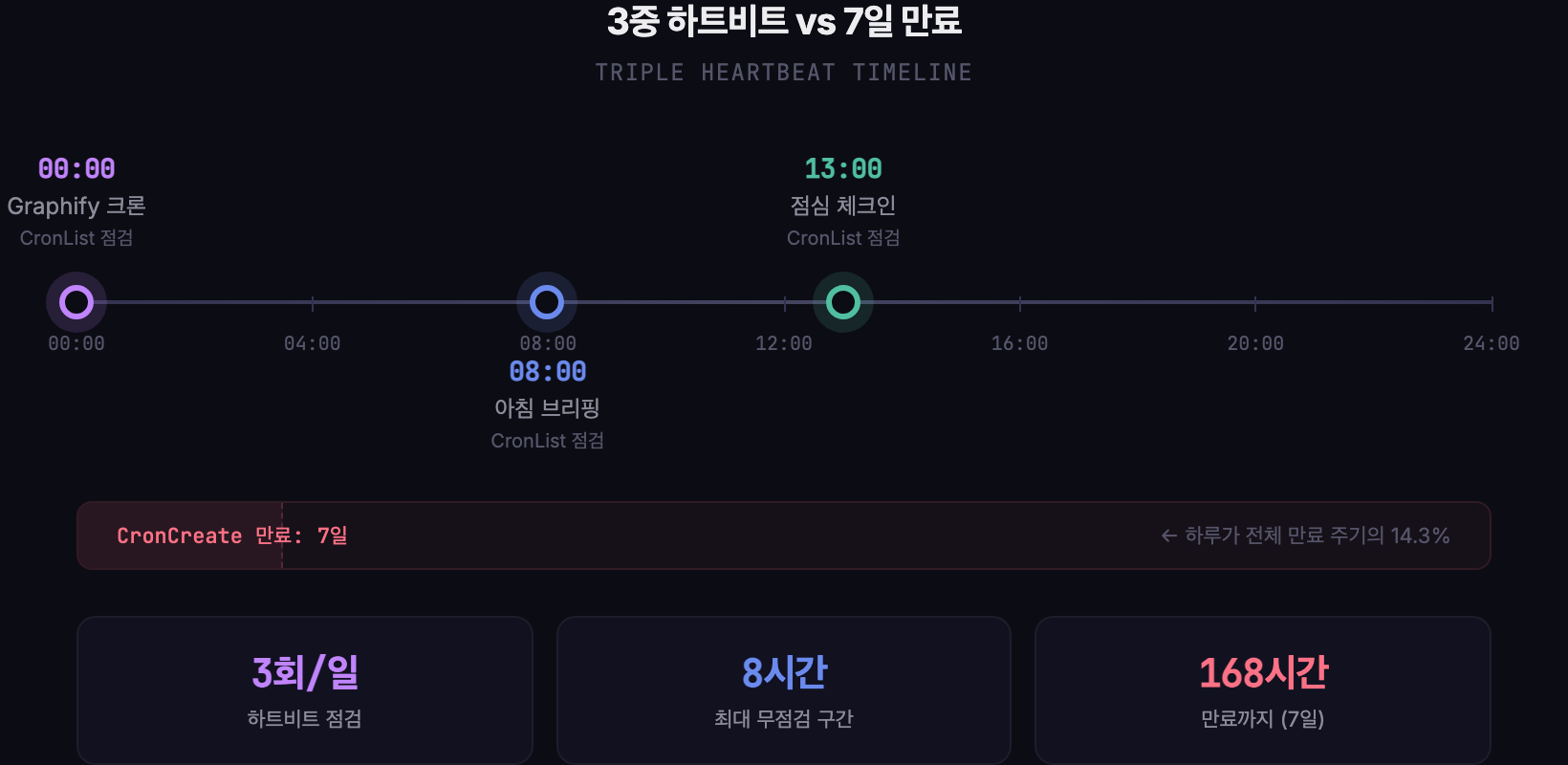
자정 (00:00) — Graphify 크론이 실행될 때, 먼저 “6개 크론 다 살아있나?” 확인해요. 아침 (08:00) — 아침 브리핑을 보내기 전에, 같은 점검을 한 번 더 해요. 점심 (13:00) — 점심 체크인에서 또 한 번 점검해요.
7일 만료 주기에 대해 하루 3회 점검하니까, 크론이 만료되어도 최대 8시간 안에 발견하고 복구해요. 두 개가 동시에 실패해도 나머지 하나가 보완하는 구조예요.
집에서 나갈 때 가스 잠그고, 현관에서 한 번 더 확인하고, 엘리베이터에서 한 번 더 생각하는 것처럼요. 강박이 아니라 합리적 중복이에요.
Sullivan의 크론 6개 중 3개에 하트비트 점검 로직을 넣었어요. 각 크론 프롬프트 파일의 첫 단계에서 CronList를 실행하고, 6개 작업명을 대조해요:
## 1단계: 스케줄 점검 (하트비트)
CronList를 실행해서 다음 6개가 모두 있는지 확인해:
- sullivan-아침브리핑, sullivan-점심체크인, sullivan-자기전회고,
sullivan-주간회고, sullivan-월간체크, sullivan-graphify
누락된 것이 있으면 sullivan-scheduler.md를 읽고 해당 작업만 재등록해.이 로직이 아침 브리핑(08:00), 점심 체크인(13:00), 자정 Graphify(00:00)에 각각 들어있어요. 핵심은 크론 프롬프트 파일을 참조하는 방식이에요. 실행 시 해당 .md 파일을 Read로 읽어서 지시를 따르는 구조라, 크론 동작을 변경하려면 파일만 수정하면 다음 발동 시 자동 반영돼요.
00:00 Graphify 크론 → CronList 점검 → 누락 시 재등록 → 그래프 빌드
08:00 아침 브리핑 → CronList 점검 → 누락 시 재등록 → 브리핑 생성
13:00 점심 체크인 → CronList 점검 → 누락 시 재등록 → 체크인 전송7일(168시간) 만료에 대해 하루 3회 점검하면 최대 무점검 구간이 약 8시간이에요. 하루가 전체 만료 주기의 14.3%이고, 점검 포인트가 그 안에 3개 있으니 실질적으로 만료 전에 잡힐 확률이 매우 높아요.
삽질 기록 — 진짜로 부딪힌 것들
설계는 깔끔했는데, 실제로 만들면서 겪은 삽질들이 제법 있었어요. “이론적으로는 되는데 실제로는 안 되는” 것들이요.
tmux가 안 뜨는데 이유를 모르겠어요. launchd에서 tmux를 실행하도록 설정했는데, 아무 반응이 없었어요. 로그를 보니 exit code 78이 찍혀 있었는데 — 알고 보니 plist에 /usr/bin/tmux라고 적었는데, Homebrew로 설치한 tmux 경로는 /opt/homebrew/bin/tmux였던 거예요. macOS에 내장된 tmux가 없으니 “설정 오류”로 조용히 실패한 거죠.
세션이 만들어지자마자 사라져요. 경로 문제를 고치고 나니 세션은 생기는데, 순식간에 사라졌어요. tmux new-session -d -s sullivan-channel "claude --channels ..." 이렇게 세션 생성과 명령어 실행을 한 줄에 넣었는데, claude 프로세스가 초기화 중 에러로 종료되면 세션 자체가 같이 사라지는 거였어요. 빈 세션을 먼저 만들고, send-keys로 명령어를 별도로 입력하는 방식으로 바꾸니까 해결됐어요. 이러면 명령어가 실패해도 셸은 살아있거든요.
재부팅하면 두 놈이 동시에 일어나요. starter(세션 시작)와 watchdog(감시자) 둘 다 RunAtLoad: true로 부팅 시 동시에 실행되니까, 둘이 같은 tmux 세션을 만들려고 경쟁하는 거예요. watchdog가 먼저 세션을 만들어버리면, starter는 “이미 있다”며 에러가 나고, 정작 watchdog는 원래 감시만 하는 놈이라 세션 소유권이 애매해지는 문제가 생겼어요. watchdog에서 RunAtLoad를 빼서 해결했어요 — 부팅 시에는 starter만 뜨고, watchdog는 나중에 주기적으로 시작되게요.
실제 구현 과정에서 부딪힌 기술적 문제들이에요.
tmux 경로 문제
launchd plist에 /usr/bin/tmux로 적었는데, Homebrew 설치 경로는 /opt/homebrew/bin/tmux였어요. macOS에 tmux가 기본 포함되지 않으므로 exit code 78(EX_CONFIG)으로 조용히 실패했어요. launchd는 PATH를 최소한으로 설정하기 때문에 절대 경로가 필수예요.
tmux 세션 생성 방식
# 이렇게 하면 claude가 죽으면 세션도 사라짐
tmux new-session -d -s sullivan-channel "claude --channels ..."
# 이렇게 하면 claude가 죽어도 셸이 살아있음
tmux new-session -d -s sullivan-channel
tmux send-keys -t sullivan-channel "claude --channels ..." Enter첫 번째 방식은 전달한 명령어가 세션의 유일한 프로세스가 돼서, 프로세스 종료 시 셸도 같이 종료되고 세션이 사라져요. 두 번째 방식은 bash 셸 위에서 명령어를 실행하는 형태라, 명령어가 실패해도 셸이 유지돼요.
--continue 플래그
처음에 claude --continue --channels ...로 이전 세션을 이어가려 했는데, 이어갈 세션이 없는 상황(최초 실행, 세션 초기화 후)에서 에러가 나서 제거했어요.
LaunchAgent 부팅 Race Condition
starter와 watchdog 모두 RunAtLoad: true로 설정하면 부팅 시 동시에 실행돼요:
부팅 → starter(RunAtLoad) + watchdog(RunAtLoad) 동시 실행
→ watchdog가 먼저 세션 생성
→ starter가 "duplicate session" 에러
→ starter가 exit 0으로 종료
→ KeepAlive.SuccessfulExit=false이므로 launchd가 재시작 안 함
→ 세션이 죽어도 즉시 복구 불가, watchdog 5분 대기해결: watchdog에서 RunAtLoad: false로 변경 + starter의 exit code를 exit 1로 변경. 부팅 시에는 starter만 실행되고, 세션이 죽으면 launchd가 exit 1을 감지해 즉시 재시작해요.
텔레그램 MCP 환경변수 세정
이건 영속성 인프라 자체보다 채널 운영 과정에서 발견한 문제인데, 인프라와 밀접하게 연결돼 있어요.
Claude Code가 MCP 서버를 스폰할 때 환경변수를 세정(sanitize)해서 TELEGRAM_STATE_DIR이 자식 프로세스에 전달되지 않았어요. 세 채널(Sullivan, PM, 일반)이 같은 기본 봇 토큰으로 폴백하면서 409 Conflict가 발생하고, 결과적으로 하나만 살아남는 상황이었어요.
runner 스크립트: TELEGRAM_STATE_DIR=.../telegram-sullivan
→ 부모 claude 프로세스에는 env 존재
→ Claude Code가 MCP 스폰 시 env 세정
→ 자식 MCP 서버: TELEGRAM_STATE_DIR 없음
→ 세 채널이 기본 디렉토리로 폴백 → 409 Conflict부모 프로세스 트리에서 ps eww로 환경변수를 찾아오는 브릿지 스크립트를 만들어 해결했어요. MCP의 .mcp.json에서 bun 직접 실행 대신 브릿지 스크립트를 경유하도록 변경한 거예요.
PM 크론의 독립 하트비트
설리반 말고, PM 에이전트 셀피(Selfy)도 같은 구조로 운영하고 있어요. 셀피는 태스크 관리, 주간 리뷰 같은 프로젝트 관리 역할을 하는데, 여기도 스케줄이 있으니 같은 영속성 문제가 있거든요.
셀피는 크론 4개(자정 하트비트, 데일리 브리핑, 주간 제안, 주간 리뷰)를 운영하고, 2중 하트비트로 점검해요. 자정(00:05)과 아침(09:03)에 각각 CronList를 확인하는 구조예요.
설리반의 3중 하트비트와 패턴은 같은데, 셀피 크론은 Sullivan보다 적으니까 2중이면 충분했어요. 중요한 건 두 시스템이 독립적으로 자기 스케줄을 점검한다는 거예요. 설리반이 죽어도 셀피는 살아있고, 셀피가 죽어도 설리반은 살아있어요.
PM 채널(셀피)은 Sullivan과 독립된 launchd + tmux + watchdog 세트를 가지고 있어요. 크론 4개를 2중 하트비트로 관리해요:
| 크론 | 시각 | 역할 |
|---|---|---|
selfy-하트비트 | 00:05 | CronList 점검 (1차) |
selfy-데일리 | 09:03 | 데일리 브리핑 + CronList 점검 (2차) |
selfy-주간제안 | 월 09:33 | 주간 태스크 제안 |
selfy-주간리뷰 | 일 09:03 | 주간 진척 리뷰 |
Sullivan 6개 크론 + 셀피 4개 크론 = 총 10개 크론이 독립적으로 운영돼요. 각 채널이 자기 크론만 점검하고, 서로의 크론에 간섭하지 않아요. 이렇게 하면 한쪽 채널이 완전히 죽어도 다른 쪽은 영향받지 않아요.
크론 관리 원칙도 중요한데 — 모든 크론은 해당 채널 세션에서만 등록해요. 다른 세션에서 등록하면 채널 라우팅이 꼬이고, session-only로 등록돼서 세션 종료 시 사라지거든요.
여기서 얻은 원칙 두 가지
이 인프라를 만들면서 두 가지 원칙을 정리했어요.
첫째, “자기 자신을 살리는 구조”를 신뢰하지 않아요. 크론이 만료되면 크론을 재등록할 수 없는 것처럼, 자기 자신에게 의존하는 복구 구조는 자기가 죽으면 무력해져요. 반드시 외부 트리거(launchd 같은 시스템 레벨)로 순환 의존을 끊어야 해요.
둘째, “언제든 깨질 수 있다”고 가정해요. 그래서 하루에 여러 번 점검해요. 7일 만료라면 하루 3번 확인하면 최대 8시간 안에 복구할 수 있어요. 완벽한 한 번의 보호보다 불완전하지만 반복되는 점검이 더 안정적이에요.
이전 글 포착 - 회고 - 인사이트 루프에서 다뤘던 루프도 비슷한 철학이에요. 한 번에 완벽한 회고를 하려는 것보다, 가벼운 포착을 매일 반복하는 게 결국 더 깊은 인사이트로 이어지더라고요. 인프라도 마찬가지예요.
이 인프라의 기반이 되는 환경 구축은 1편: 항상 대화할 수 있는 환경 만들기에서 다뤘고, 세션 간 검증 기록을 어떻게 유지하는지는 고쳤습니다(안 고침)에서 다른 각도로 살펴볼 수 있어요. verified-fix는 “검증 결과의 영속성” — 한 세션에서 확인한 게 다음 세션에서도 이어지는 것 — 에 대한 글이고, 이 글은 “시스템 전체의 영속성”에 대한 이야기예요.
정리하면 두 가지 설계 원칙이에요:
순환 의존은 외부 트리거로 끊는다. 자기 자신을 갱신하는 구조는 자기가 죽으면 작동하지 않아요. CronCreate 만료 → 재등록 cron도 만료 → 재등록 불가. 이 순환을 시스템 레벨(launchd)의 외부 트리거로 끊는 것이 가장 안정적이에요.
“언제든 깨질 수 있다”고 가정하고, 하루에 여러 번 점검한다. 7일 만료에 대해 하루 3회 점검하면 실질적인 위험 구간은 최대 8시간이에요. 완벽한 단일 보호보다 불완전하지만 반복되는 다중 점검이 더 안정적이에요.
이 글에서 다룬 것은 “시스템 인프라의 영속성”이에요. 1편: 항상 대화할 수 있는 환경 만들기에서 채널 모드 기반의 환경 구축을 다뤘고, 4편: 포착 - 회고 - 인사이트 루프에서 다룬 루프의 자동 실행이 바로 이 인프라 위에서 돌아가는 거예요.
고쳤습니다(안 고침)에서 다룬 것은 “검증 기록의 영속성” — 한 세션에서 확인한 결과가 다음 세션에서도 이어지는 문제예요. 같은 “영속성”이라는 단어를 쓰지만 스코프가 달라요. verified-fix는 파일 하나의 상태 유지, 이 글은 시스템 전체의 생존이에요.
마무리 — 파트너라면 살아있어야 해요
AI를 도구로 쓸 때는 필요할 때 켜고, 끝나면 꺼도 괜찮아요. 그런데 “사고 파트너”라고 부르려면, 제가 아침에 일어났을 때 거기 있어야 해요. 재부팅했다고, 7일이 지났다고 사라지면 — 그건 파트너가 아니라 도구예요.
이 인프라를 만들고 나서부터 설리반이 아침마다 브리핑을 빠뜨리지 않게 됐어요. 당연한 것 같지만, 당연하게 만들기까지가 당연하지 않았어요.
혹시 AI 에이전트를 자동 스케줄로 운영하고 있다면, 한번 점검해보세요. “이 스케줄이 만료되면, 누가 재등록하지?” 거기에 답이 없다면 — 외부 트리거 하나 만들어두는 게 마음 편할 거예요.
이 시리즈의 다른 글
- 항상 대화할 수 있는 환경 만들기 — Python 봇에서 Claude Code 채널로
- 채널 시스템으로 페르소나 분리하기 — 같은 프로젝트, 다른 역할
- AI 사고 파트너의 대화 규칙 설계 — '왜?'가 아니라 '뭐?'를 묻는 이유
- 포착 → 회고 → 인사이트 루프 — 하루의 리듬이 시스템이 되는 과정
- 영속성 체인으로 세션 안정성 확보 — AI가 꺼지지 않게 만드는 4레이어